[未完成的草稿] 这是数据流,愚蠢的。
Groq 比 Mellanox 更大。
非理性分析在半导体行业投入巨资。职位会随着时间的推移而变化,并定期更新。
非理性分析在半导体行业投入巨资。
职位会随着时间的推移而变化,并定期更新。
意见为作者个人观点,不代表过去、现在和/或未来的雇主。
本新闻稿中发布的所有内容均基于自 2011 年以来的公开信息和独立研究。
本时事通讯并非财务建议,读者在投资任何证券之前应始终进行自己的研究。
请随时通过电子邮件与我联系:[email protected]
大约两个月前,Nvidia 收购了 Groq,通过“非独家”许可协议获得了所有有价值的知识产权,并且(更重要的是)雇佣了所有人才。
我长期以来一直讨厌 Groq。
这是 2024 年 2 月的一篇旧帖子,专门写在 Groq 上。
我的第一反应是这笔交易是为了获得特朗普政府批准 H200 出口而进行的贿赂。许多其他人公开表达了这一观点,也私下给我留言。
甚至许多英伟达自己的员工也认为这是贿赂。
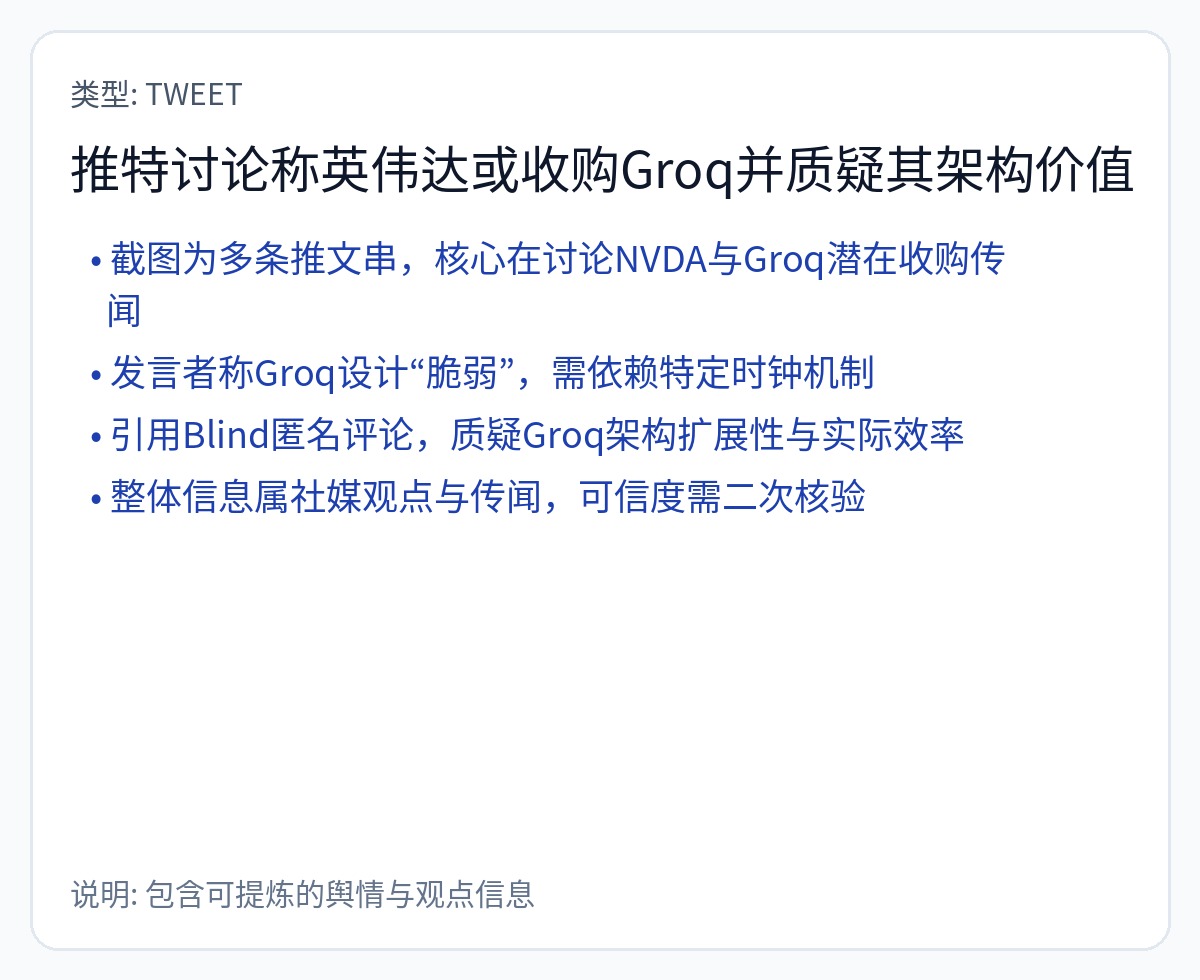
注意:Blind 是一个(尤其是恶性的)社交媒体平台,要求您使用工作电子邮件进行注册。但他们不会检查您是否仍在您签约的公司工作。
但经过几个月的思考,并考虑到人工智能经济学的最新发展,我已经完全投降了。
它始于一个简单的(非工程)前提。
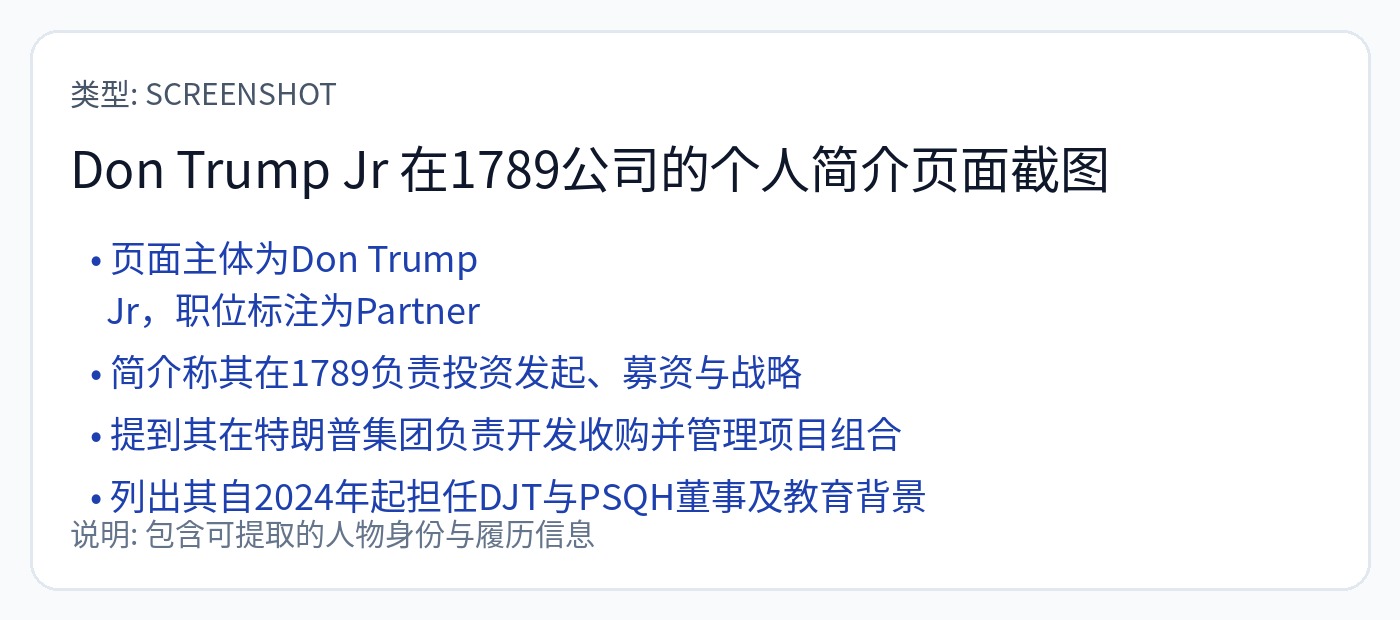
在与 NVIDIA 达成交易之前不到三个月,Groq 就以 70 亿美元的估值筹集了资金。 Don Jr 风险投资公司(1789 Capital)参与了本轮融资。
$14B 的收购将使 Don Jr. 在不到三个月的时间内获得 100% 的投资回报。感觉像是理论上贿赂的适当规模。
但 20B 美元的交易实际上使贿赂理论无效。太高了。
20B 美元是那种说“他妈的闭嘴,停止谈判,下周之前滚进 Nvidia 办公室”的钱。
这就是发生的事情。

从这笔交易被公开泄露/宣布之日起,仅用了四个工作日就让 Groq 人才进入并开始工作。显然,英伟达存在紧迫性,并且在这方面还有更多证据......
我的感觉是 OpenAI 正在竞购 Groq,而 Jensen 击败了他们。
我猜 Groq 的员工对真实的金钱比理论的金钱更感兴趣。这些年来,在纸面上富有,但在现实生活中贫穷,一定不会是一种很好的感觉,像小丑一样招摇过市。
继续这个介绍,让我提出一篇旧文章,一半是关于 Tenstorrent,一半是关于为什么我认为(当时)绝大多数人工智能硬件初创公司都会死掉。
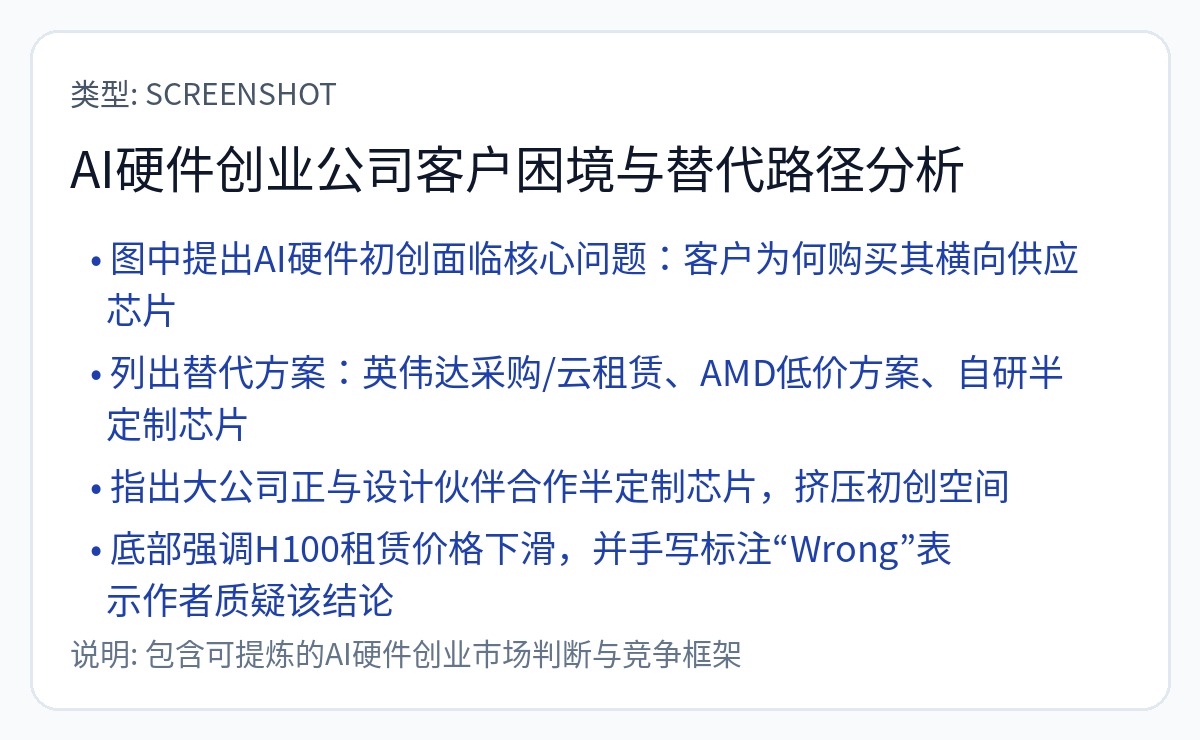
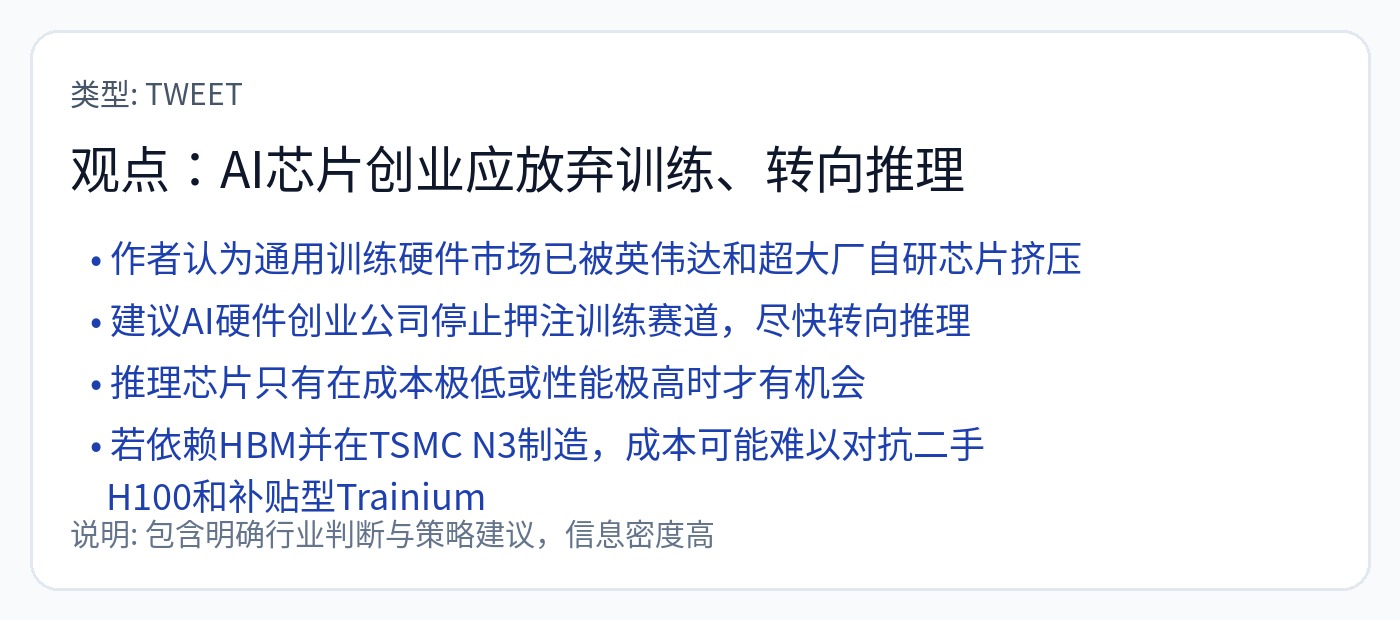
在这次深入研究中,我有四个主要目标:
解释之前对所有人工智能硬件初创公司的负面看法的完全逆转。
解释一下之前对 Groq 架构的仇恨的完全逆转。
涵盖所有有趣的人工智能硬件初创公司。 (Groq、Cerebras、D-matrix、SambaNova、Etched、Positron、MatX、Tenstorrent、Taalas)
解释一下为什么这一切都与 SRAM 无关。
https://en.wikipedia.org/wiki/It%27s_the_economy,_stupid
这是数据流,愚蠢的。
<一切都更好的缩略图>
这是未完成的草案
我目前正在与 MatX、Etched、Taalas 和 Positron 进行谈判,以获得技术信息以及发布与其部分相关的内容的许可。
其他人工智能硬件初创公司有足够的公开信息来涵盖。
鉴于 Groq 交易对公开市场的重要性,我决定发布一份早期(非常不完整)的草案,其中仅包含 Groq,不包括所有初创公司。
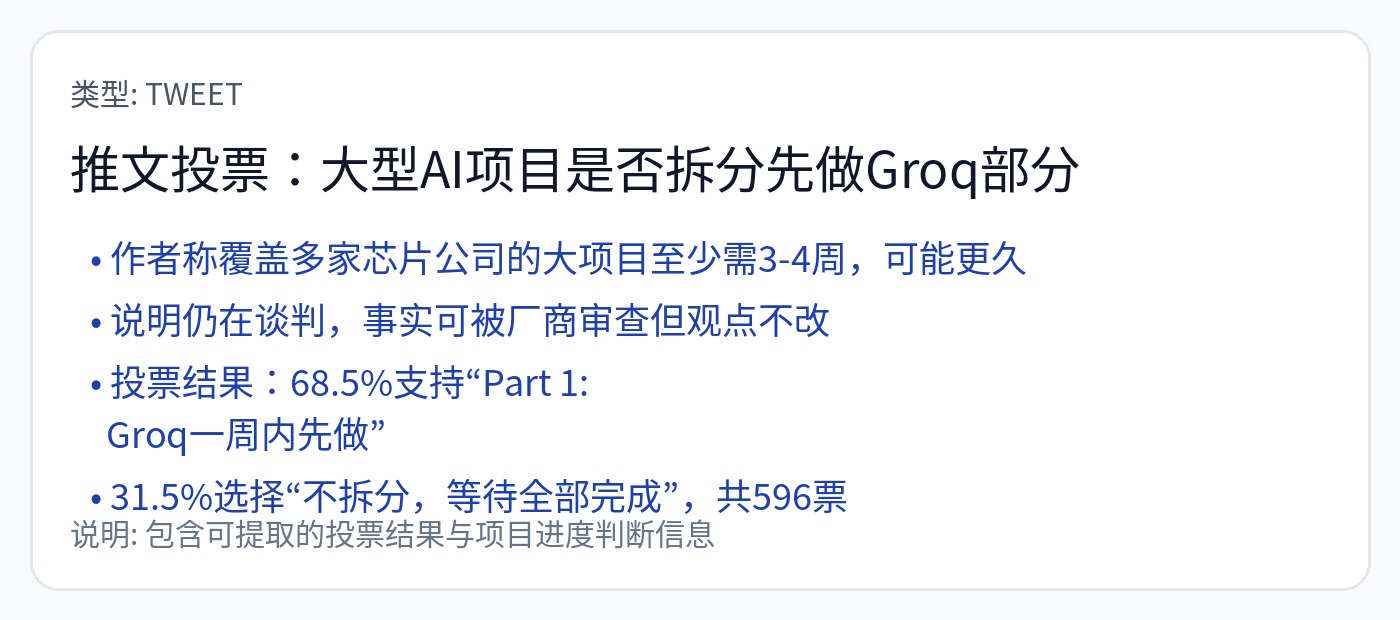
讽刺的是,我认为 Groq 的交易比 Mellanox 的规模更大。
这里完全逆转/投降。多年来我一直在攻击 Groq。先前的观点和新的观点都是有原因的……希望在[5+6]节中能够得到一些连贯的解释。
<> 中有各种注释(给我自己),因为我计划复制这篇文章并稍后填写缺失的部分。对这种工作质量不满意,但不得不做出妥协。
人工智能硬件初创公司可以查看其各个部分的私人草稿,辩论事实并否决他们希望保密的信息。但没有意见改变。将会有一些来回的过程,可能需要几个月的时间。确实希望对所有四家正在谈判的初创公司进行适当的技术报道。
<todo:重写本节作为最终帖子>
<todo:为最终帖子更新披露内容>
在撰写本文时,我的交易账户处于以下状态。
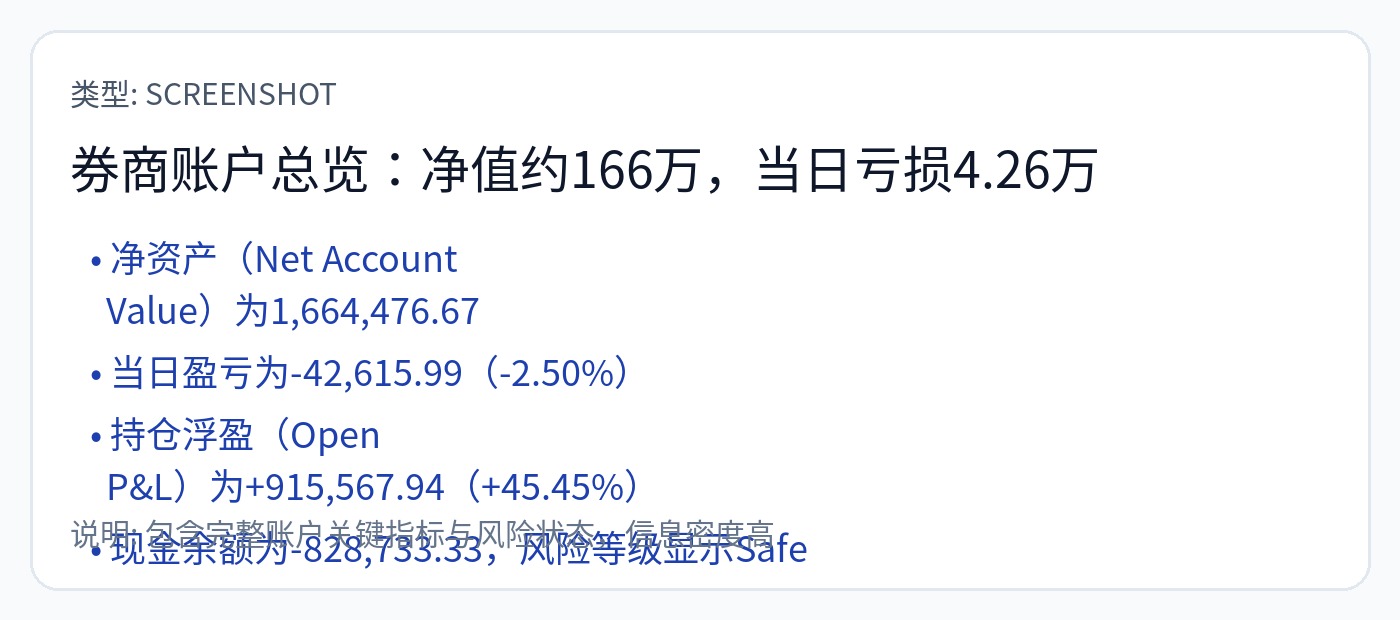


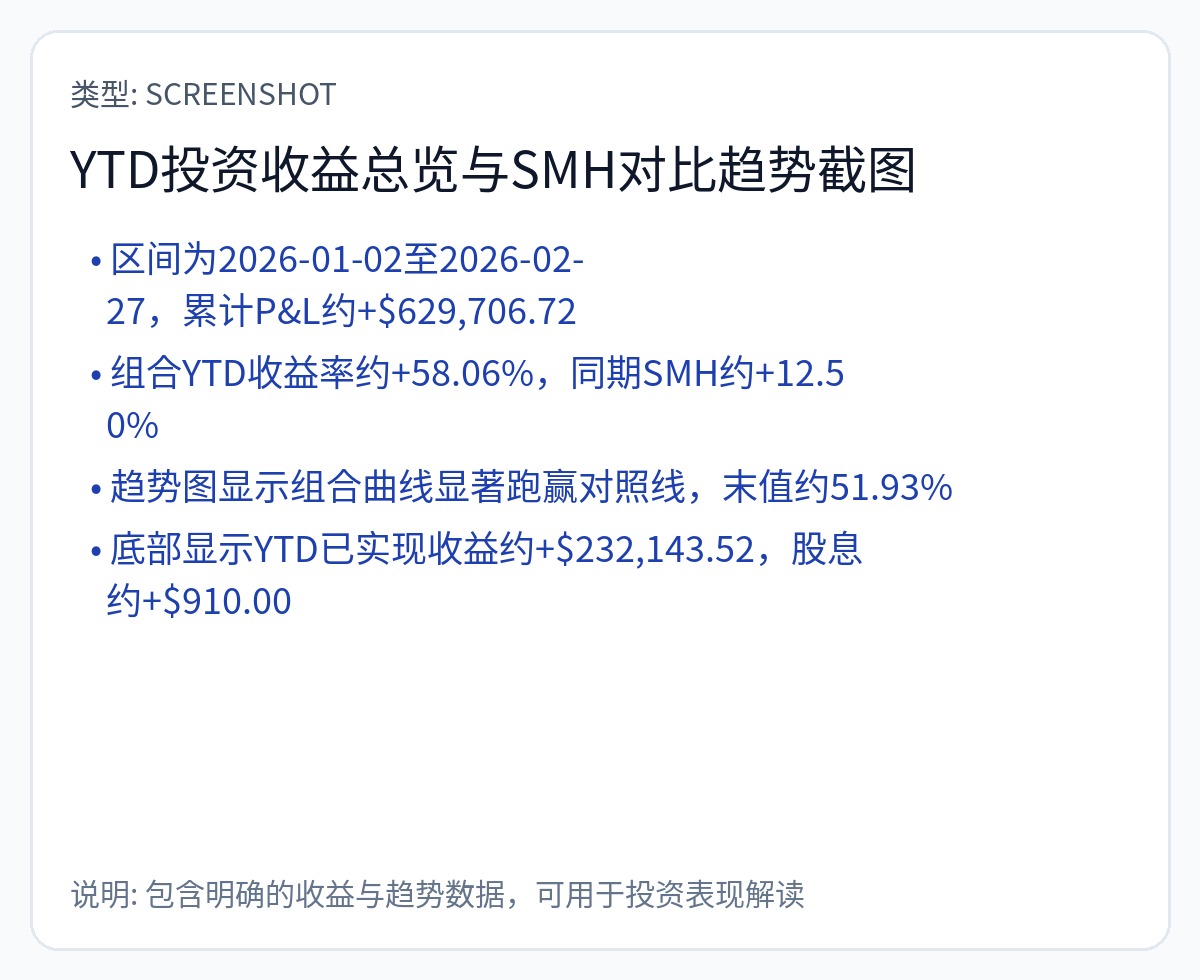
这是带有一些综合统计数据的长期唯一账户。
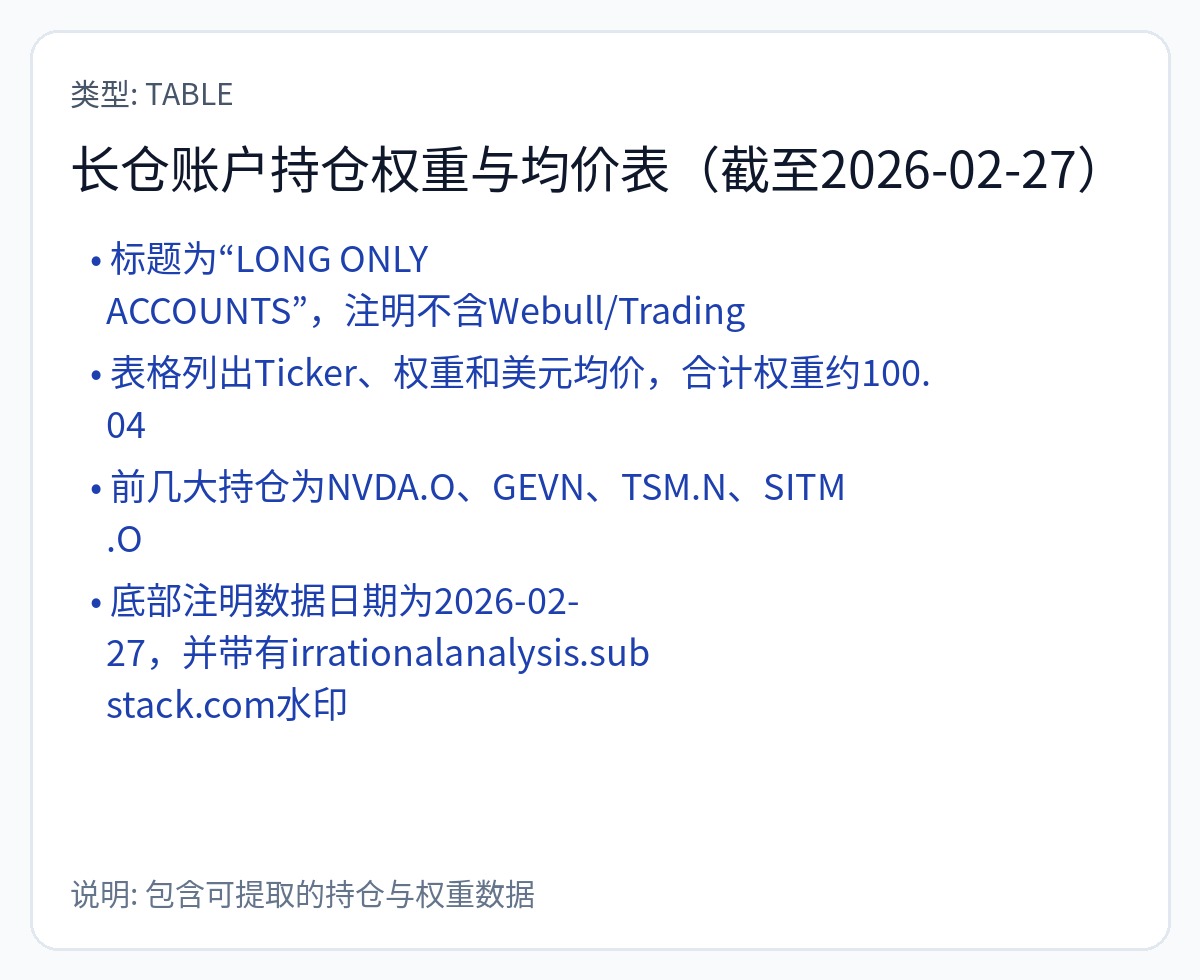

你可以认为我有偏见,因为我拥有大量的 Nvidia 股票和看涨期权。但事实上,我有这些立场是出于正交的原因。

你知道我的偏见,你自己拿主意吧。
也许我比你更了解半导体?
内容:
如何描述任何计算机。存储器层次结构 存储器访问/路由计算结构 芯片间通信结构
如何描述任何计算机。
内存层次结构
内存访问/路由
计算结构
芯片到芯片的通信结构
普通架构 CPU (AMD Genoa-X) CPU (Intel Saphire Rapids) GPU (Nvidia GB300 // Blackwell Ultra) TPU (Ironwood // V7) Tenstorrent <todo> Positron <todo>
普通架构
CPU(AMD Genoa-X)
CPU(英特尔蓝宝石急流)
GPU(Nvidia GB300 // Blackwell Ultra)
TPU(铁木 // V7)
Tentorrent <todo>
正电子<全部>
异常架构 <全部> D-Matrix <全部> Cerebras <全部> SambaNova <全部> 蚀刻 <全部> MatX <全部>
异常架构<全部>
D 矩阵 <todo>
大脑<全部>
SambaNova <待办事项>
蚀刻<全部>
MatX <全部>
塔拉斯:非常异常<todo>
Groq:Batshit 疯狂和精神错乱
Nvidia 令人难以置信的 IP 与 Groq 风格架构时钟转发 SerDes 混合接合领先的热团队理论光学全局时钟的协同作用
Nvidia 令人难以置信的 IP 与 Groq 风格架构的协同作用
时钟转发 SerDes
混合键合
领先的热团队
理论光学全局时钟
可能的 Nvidia/Groq 产品的模型
任何白痴都可以建造一座桥梁 // 疯狂计算机的黄金时代
[1] 如何描述任何计算机。
今天的材料会很复杂,所以我们需要一个通用的框架。
例如,Cerebras 喜欢对 Nvidia 提出废话,忽略了每个核心非常小的细微差别,因此编译器需要在运行前将神经网络图完美地映射到一个巨大的网格上。
这是“内存访问/路由”如何成为计算机的关键属性的一个很好的例子。
我相信任何计算机都可以通过以下方式合理地描述:仅使用四个属性就可以对截然不同的体系结构进行高级比较。
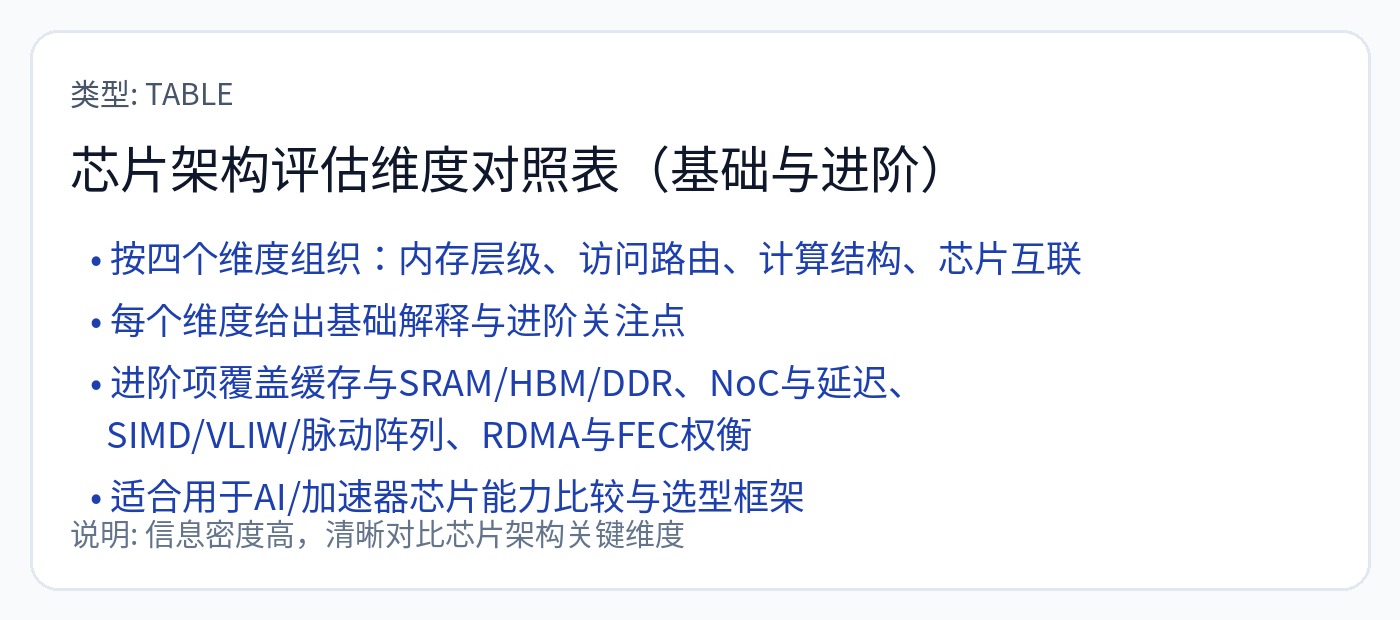
我之前有一本关于计算机体系结构的指南,但想为这篇文章重写它。非常奇怪的架构需要以新的方式进行覆盖。
[1.a] 内存层次结构
描述这个概念的经典方法是使用金字塔。

沿着金字塔往上走会带来指数级更好的性能和更高(更差)的成本。
在过去,大多数计算机(基本上是各种 CPU)都有 3 级缓存。
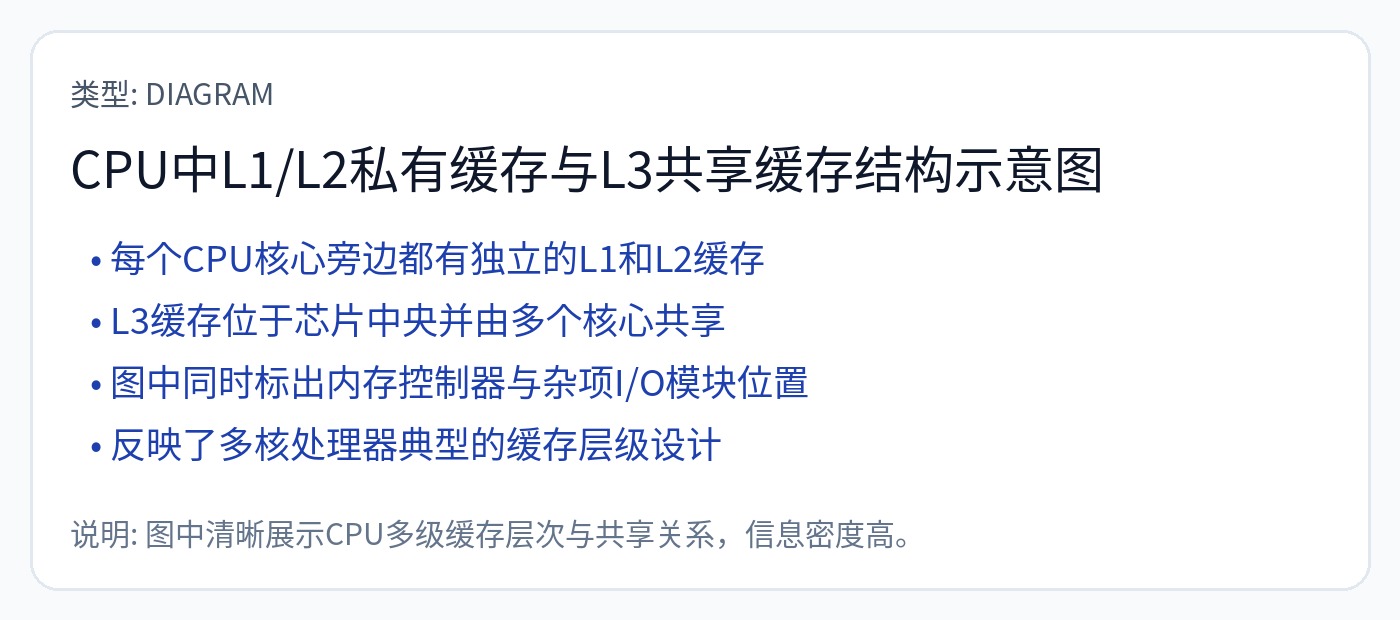
高速缓存(几乎总是)由 SRAM 制成,但与 SRAM 不同。
在运行时,计算核心需要决定哪些内存应该放在哪里。例如,一个特定的变量是否应该存储在 L1 中以实现超快速访问,或者踢到 L3 以实现快速访问,或者因为它不重要而一直踢到 DRAM?
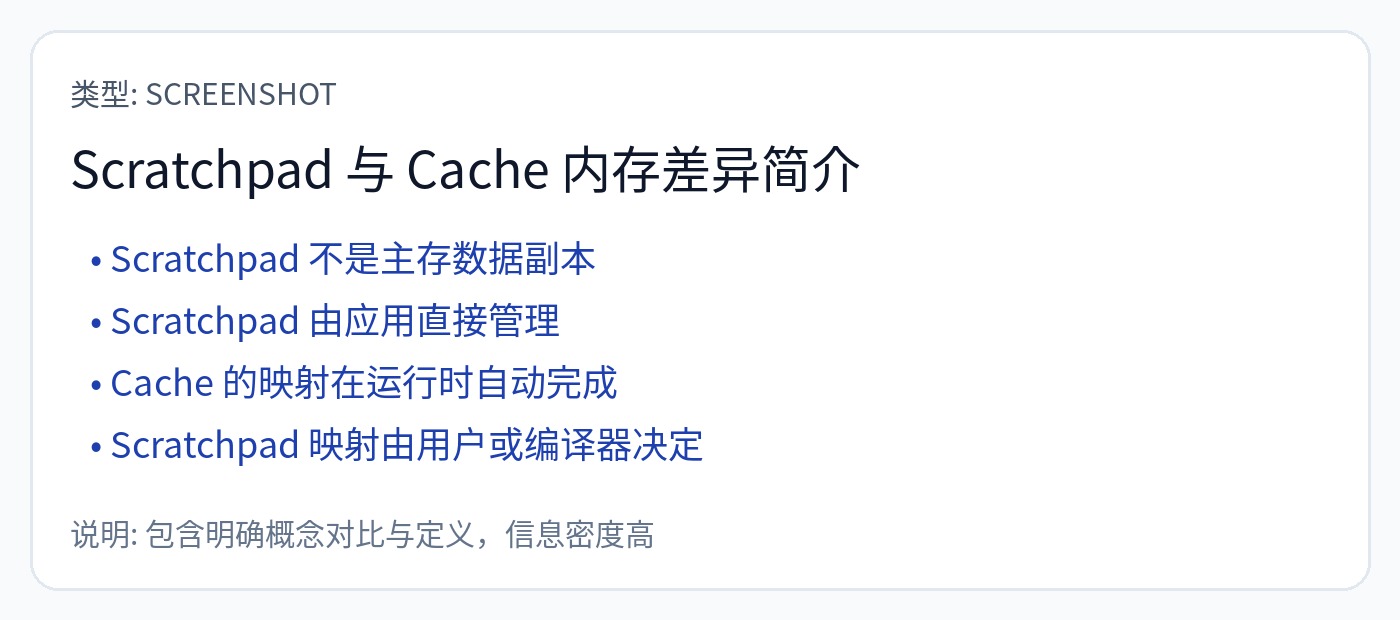
如果由硬件做出这些决定,则 SRAM(片上存储器)就是一个高速缓存。
如果软件做出这些决定,SRAM(仍然是片上存储器)就是一个“暂存器”,而不是缓存。
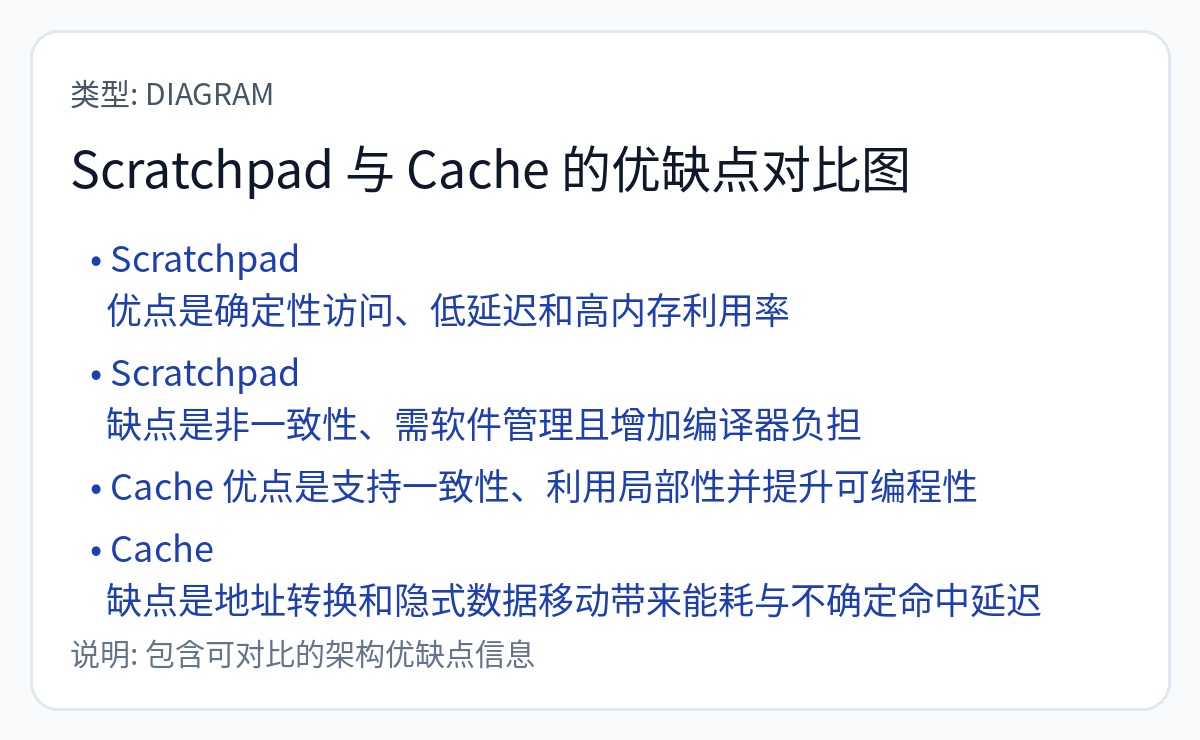
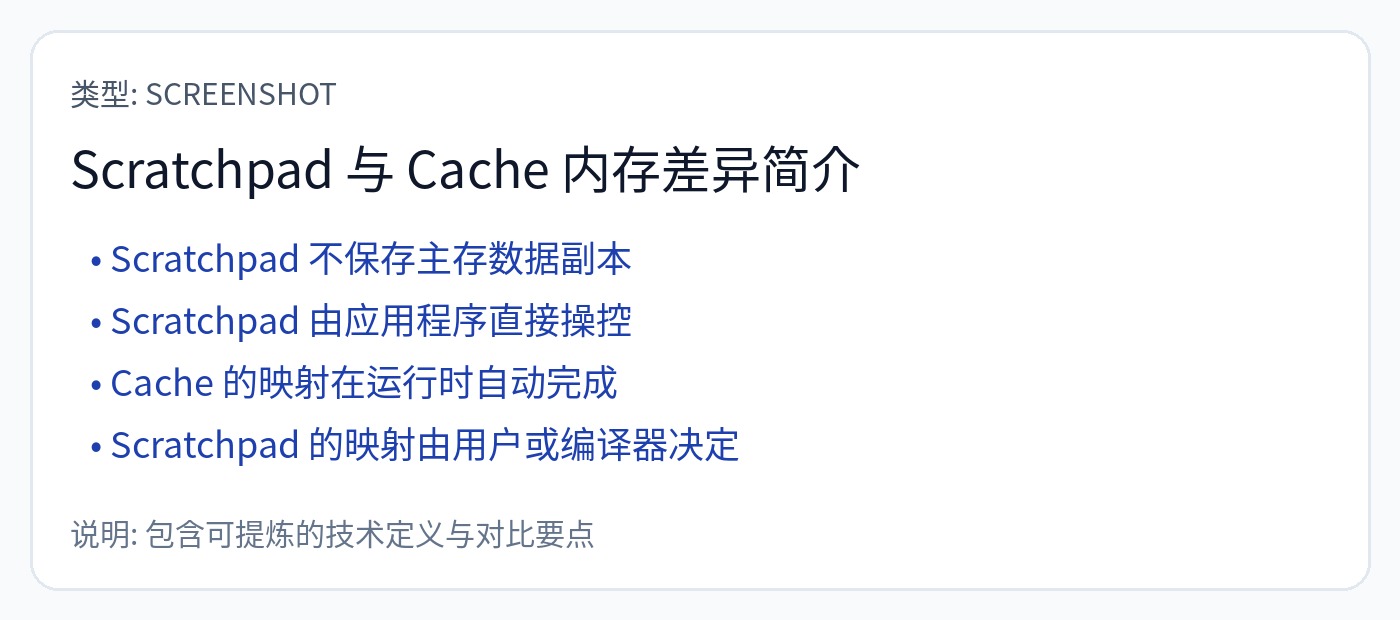
这是一个非常重要的细微差别,但大多数公共言论完全搞砸了。坦白说令人气愤。彻底改变了系统的基本方面,从内存地址映射到计算硬件复杂性再到编程模型。
使用原理#1(内存层次结构)评估计算机体系结构时应该问的关键问题:
系统是否使用缓存或暂存器。
缓存未命中的惩罚是什么?
是否有多层缓存或暂存器?
高速缓存/暂存器与 DRAM 或其他内存层的比率是多少?
[1.b] 内存访问/路由
现在让我们在堆栈中上一层。
给定任意一块内存,任意计算块如何访问所述内存?
是的,数据通常从 HBM 堆栈移动到逻辑芯片。金星给你。但是数据如何在逻辑芯片内移动呢?
关键概念是NoC,即片上网络。 Ian Cutress 博士对此有一个很棒的视频。互联网上最好的。
两种主要架构用于连接芯片上的元件。
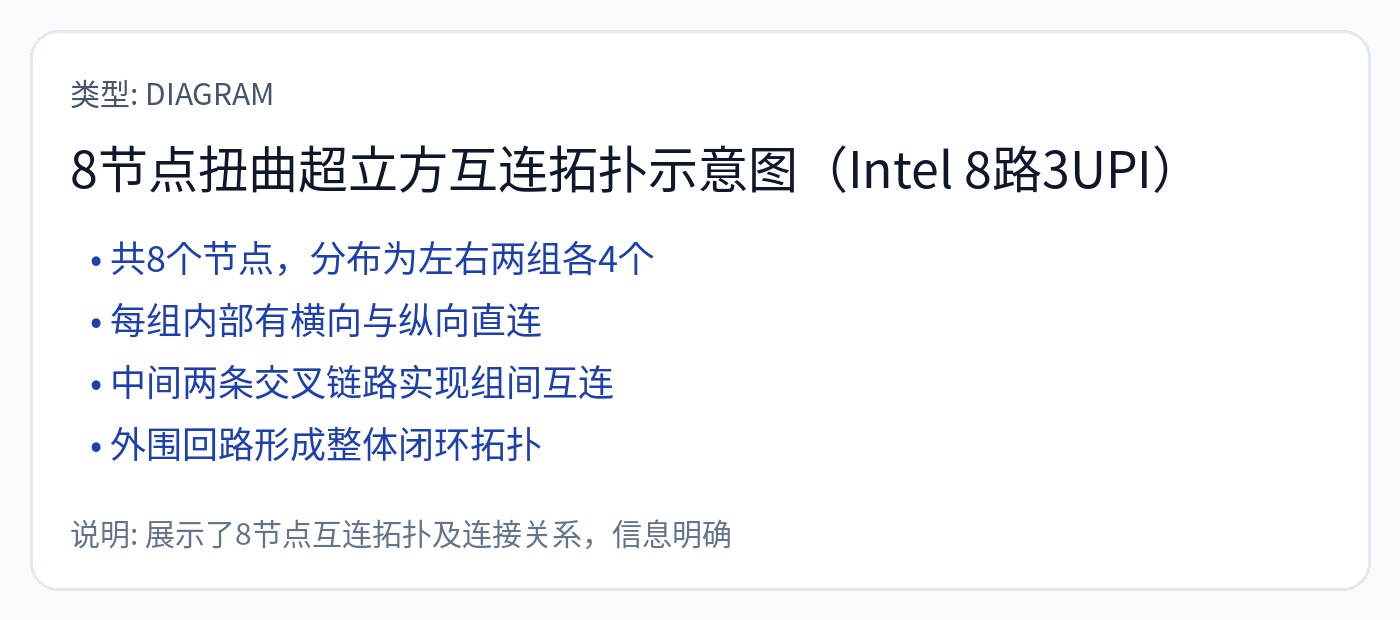
第一个是一个戒指或一组戒指。
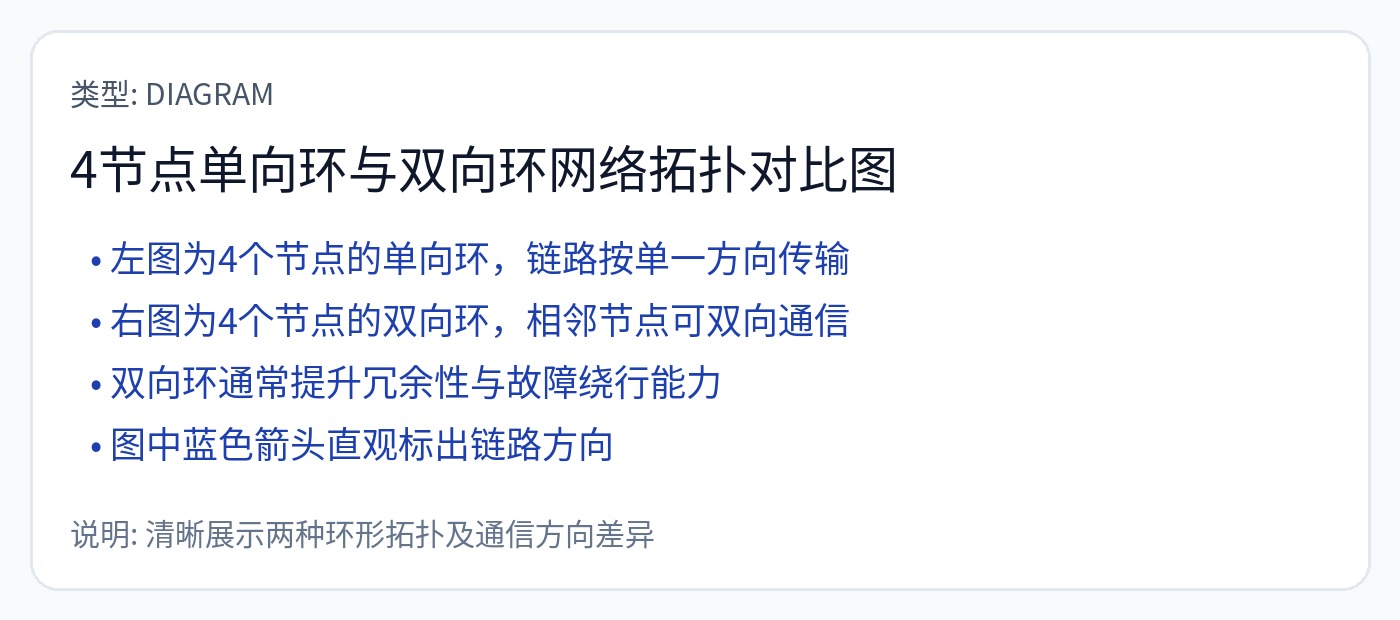
第二种主要类型称为网格。
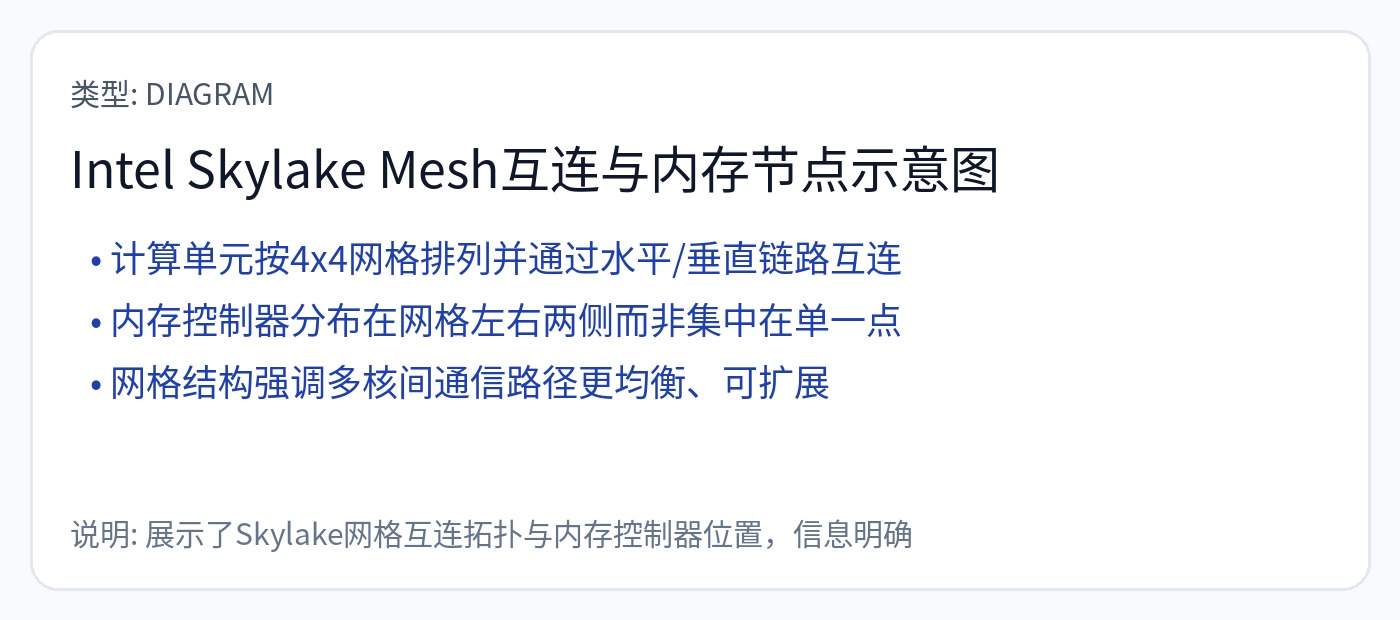
以及网格的衍生物。
还有很多更有趣的组合,为了节省时间,我将跳过这些组合。其中许多都是专有的,我可能不应该在这里写它们。
您可以拥有多个环总线,其中某些元素仅位于特定环上。
还可以有一个交叉开关,将一组元件分组,然后通过环或网连接到更宽的芯片。
并非芯片上的所有元件都需要有到每个其他元件的路径。

请记住,内存(SRAM 块、HBM 堆栈)只是 NoC 上的一个节点。
片上网络的设置方式非常重要。
[1.c] 计算结构
该资源是一颗隐藏的宝石。
https://www.lighterra.com/papers/modernmicroprocessors/
为了节省时间,我会走得很快,并且经常挥手。无论如何,从后面几节的示例中学习可能会更容易。
计算机以称为指令的基本单位执行数学运算。
示例说明:
将一个字节从内存加载到寄存器
添加
逻辑与/或/异或
……
现在的关键问题是:
你的电脑有多“漂亮”?
计算机一次使用多少个数据操作数?
支持哪些数据格式?
[1] 高级计算核心使用很酷的策略,例如分支预测、推测执行和乱序执行。这些策略都以某种方式“破坏”了原来编译的代码。硬件本身会实时找出汇编代码中的快捷方式。高级计算机(基本上是 CPU)以面积/功耗和并行性/可扩展性为代价提供了巨大的性能提升。这是 CPU 不适合 AI 的主要原因。
[2] GPU 和 CPU 之间的根本区别在于扭曲/波浪的概念。
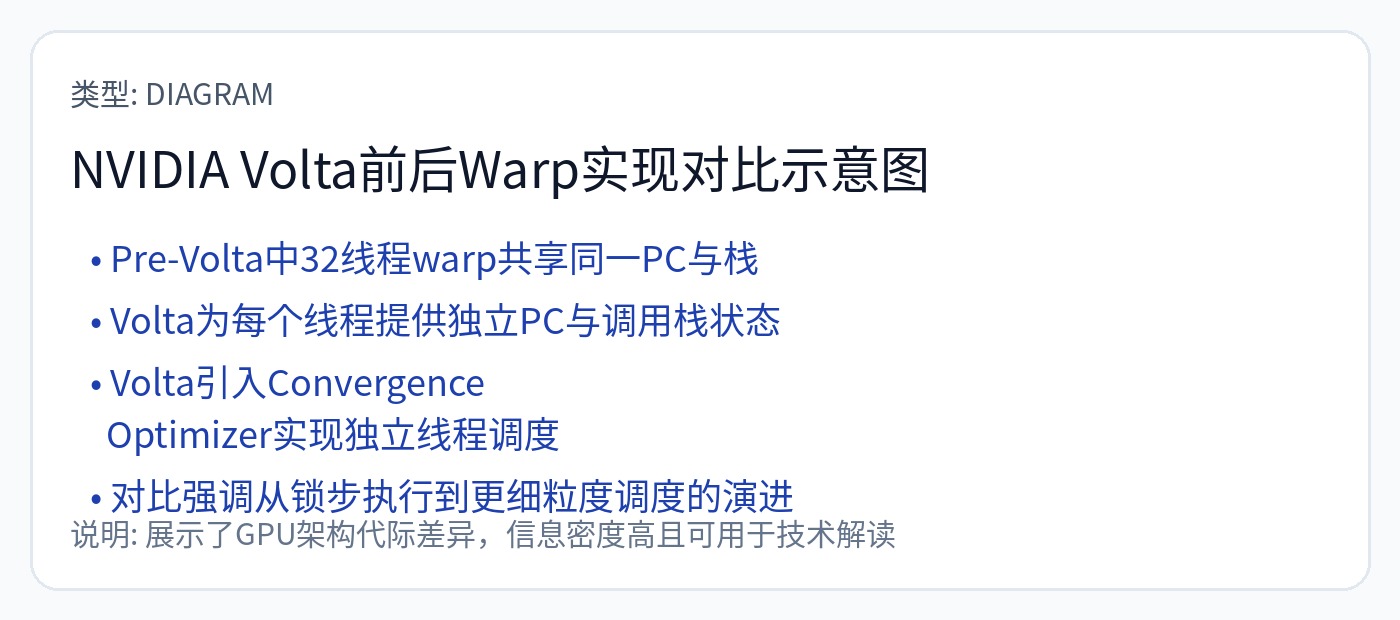
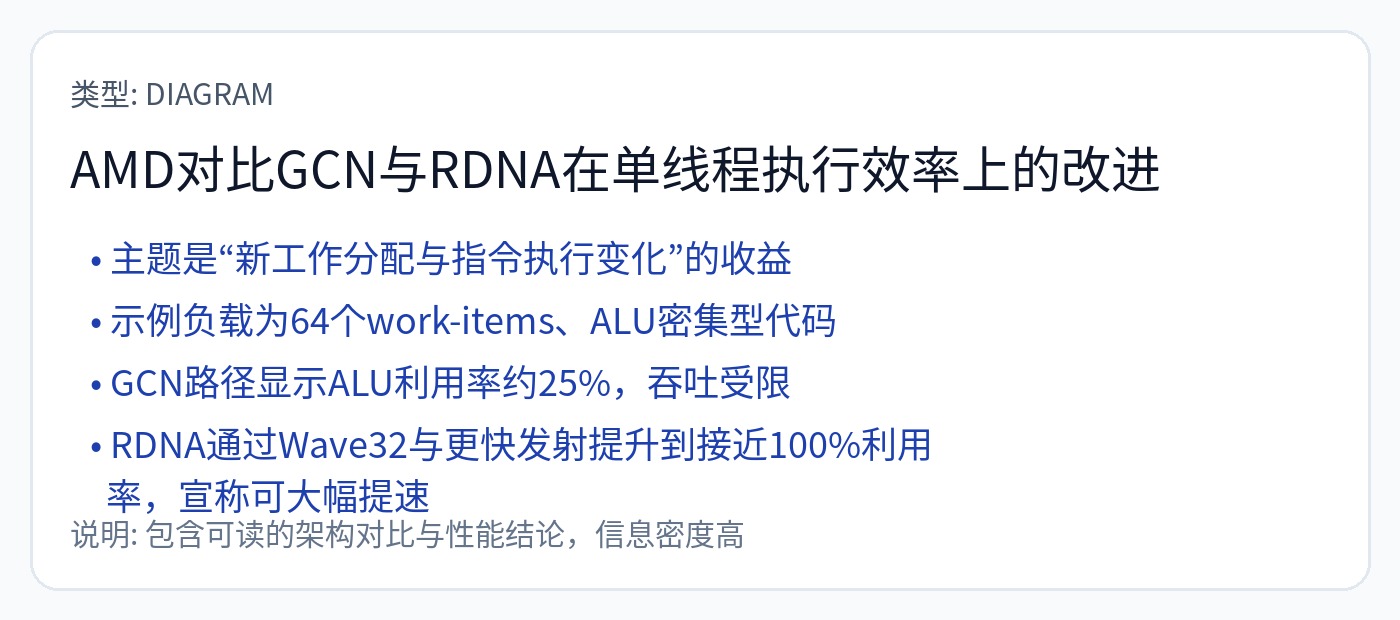
单指令、多数据 (SIMD) 是 GPU 工作的架构原理。 Nvidia 在数据中心使用 32 元素“扭曲”,而 AMD 使用 64 元素“波浪”。所有 AMD 架构都是 Wave64,但几年前他们将游戏架构迁移到 Wave32。
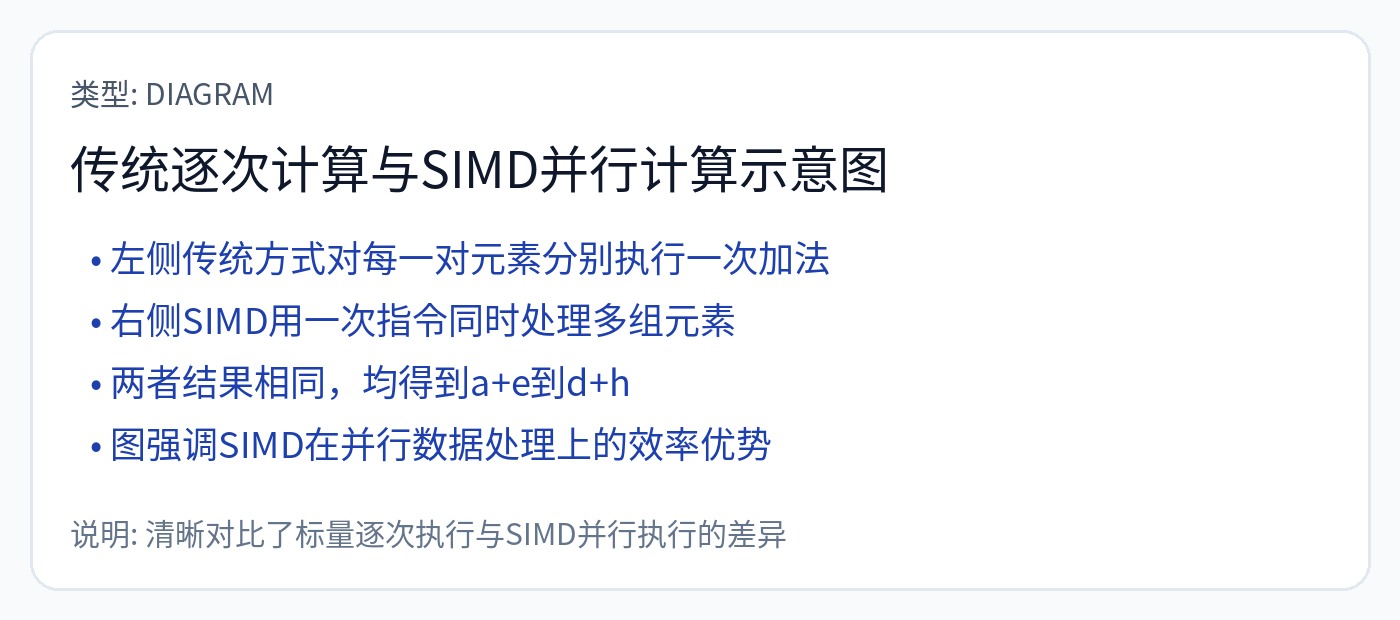
多年来,CPU 添加了 SIMD 指令。很多 SIMD 指令...
https://en.wikipedia.org/wiki/List_of_x86_SIMD_instructions
https://en.wikipedia.org/wiki/AArch64#Scalable_Vector_Extension_(SVE)
GPU 在人工智能工作负载中占据主导地位,因为它们(这过于简单化了……)大多是纯 SIMD 机器,而 CPU 则装有 SIMD。
本文要介绍的许多奇特架构都是 SIMD 机器,但灵活性远不如 GPU。
我们来谈谈数据格式和稀疏性。
在过去,只有单精度(32 位)和双精度(64 位)浮点数才重要。
对于 AI,浮点数和整数低至 4 位很重要。
例如,Cerebras 愚蠢地不支持 8 位浮点数。但他们仍然不支持这个基本功能。 Nvidia 已经有了 4 位浮点数,AMD 很快就会支持 FP4。
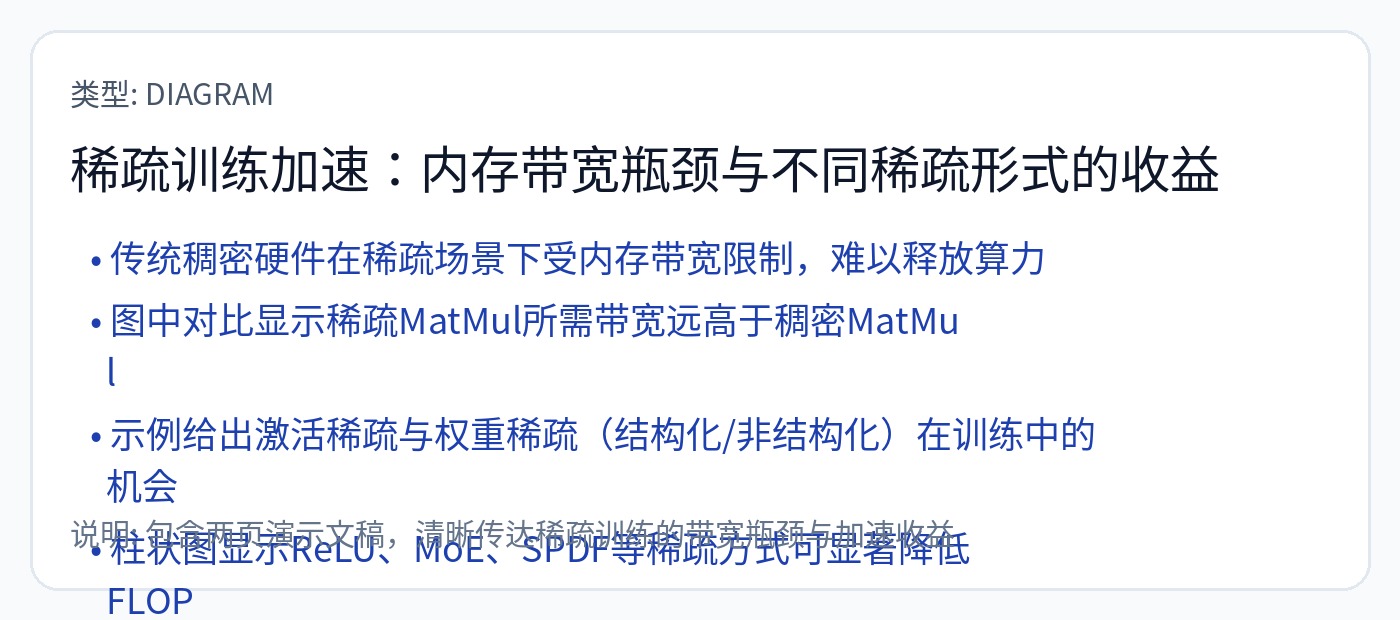
他们还对非结构化稀疏性提出了大胆的主张。多年来我一直向机器学习人员询问这个问题,直到今天他们都没有发现这个功能的用途。
使用精度较低的数据格式,您会损失一些准确性,但会获得更多的吞吐量。
对于某些工作,准确性的损失可以忽略不计。
最后,让我们简单介绍一下超长指令字(VLIW)。
在这里深入探讨:
简短的回答(过于简单化)是……
VLIW = SIMD,但指令可以完全不同,但有许多限制。
指令“捆绑”(例如……1 个加载、5 个乘法、2 个加法、1 个存储、2 个分支)在块中进行操作。编译器必须调度每个包/块。
非常简化的硬件设计,恶魔般的噩梦编译器负担。
[1.d] 芯片到芯片的通信结构
最简单的芯片到芯片(c2c)通信结构是全对全(all-to-all)。
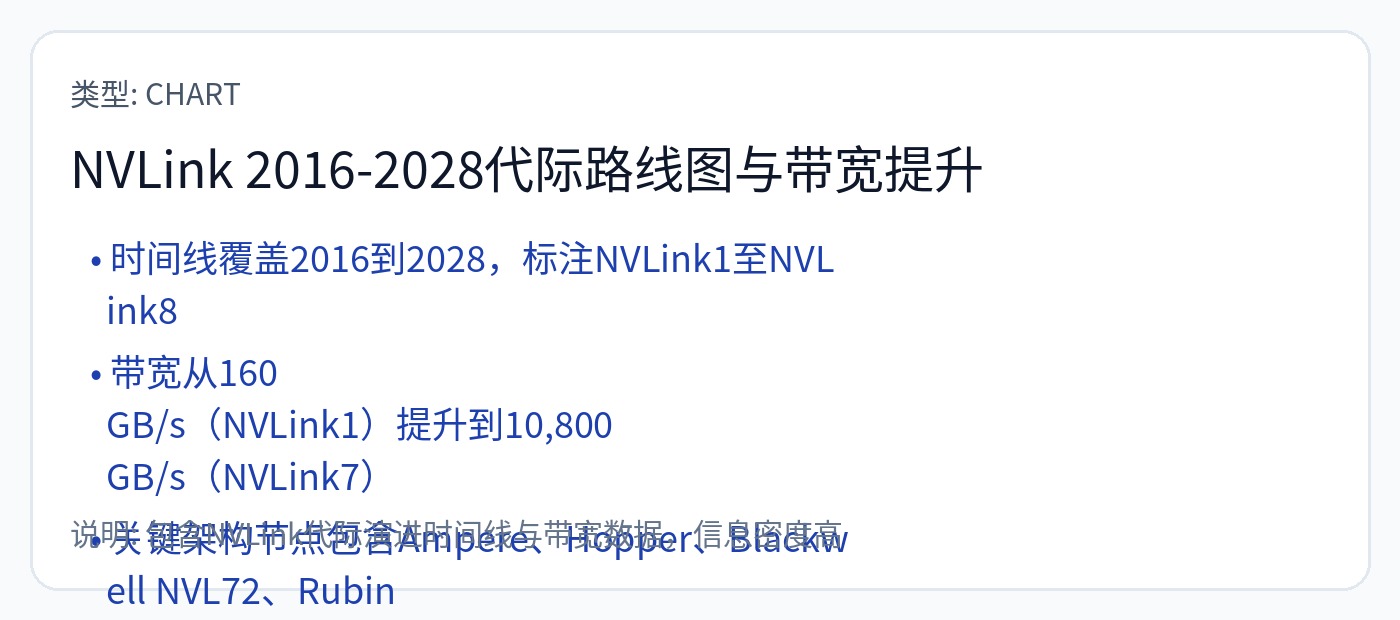
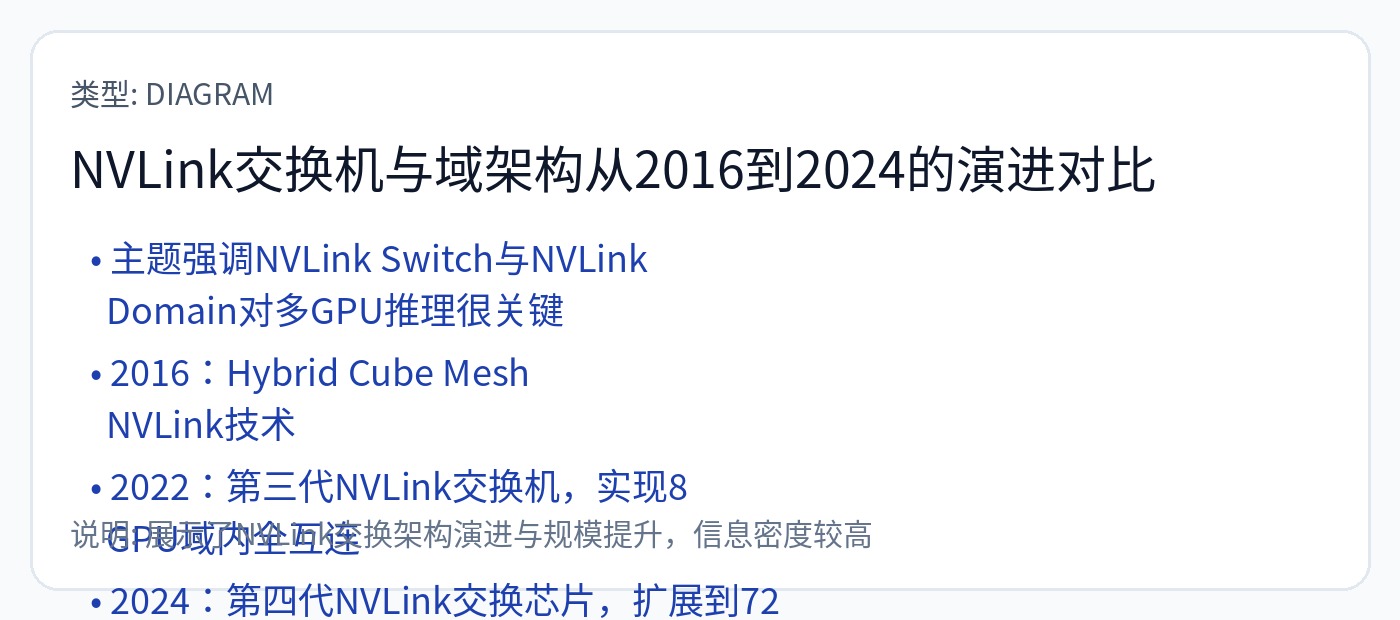
Nvidia 使用完全的全无源铜,这在性能和灵活性方面是最好的,但在成本和可靠性方面是最差的。询问有关传说中的有线背板的信息。 :)
每个 GPU 都可以通过单跳以全带宽与 NVL72 域中的任何其他 GPU 进行通信。
谷歌在他们的 Ironwood TPU 中使用了 3D-Torus。
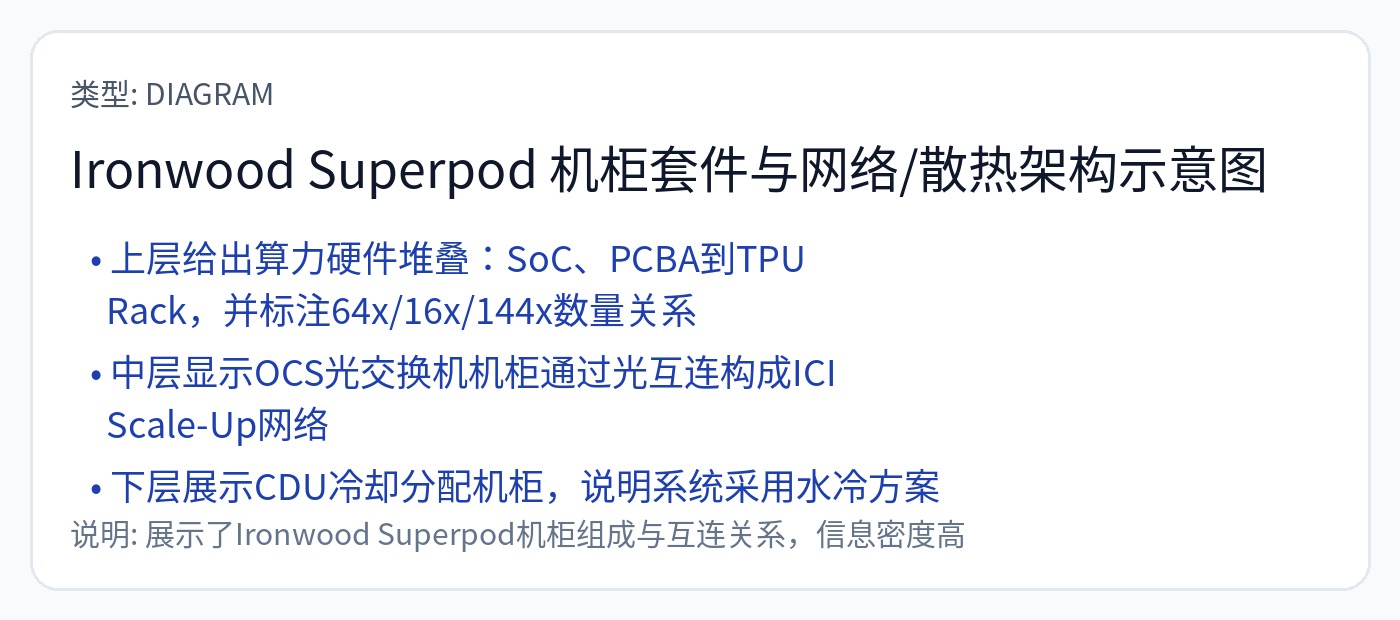
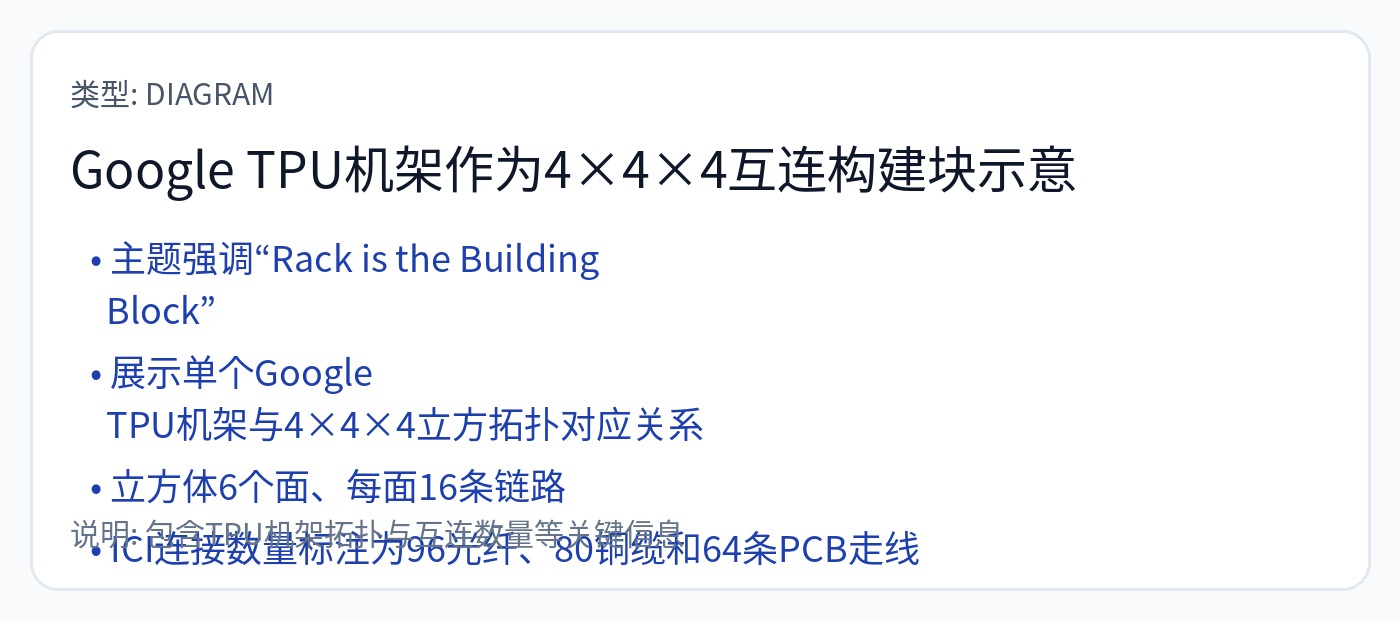
每块 4x4x4 (64) TPU 芯片都在机架内进行电气连接。跨机架连接是通过基于MEMS的OCS进行光学连接的。
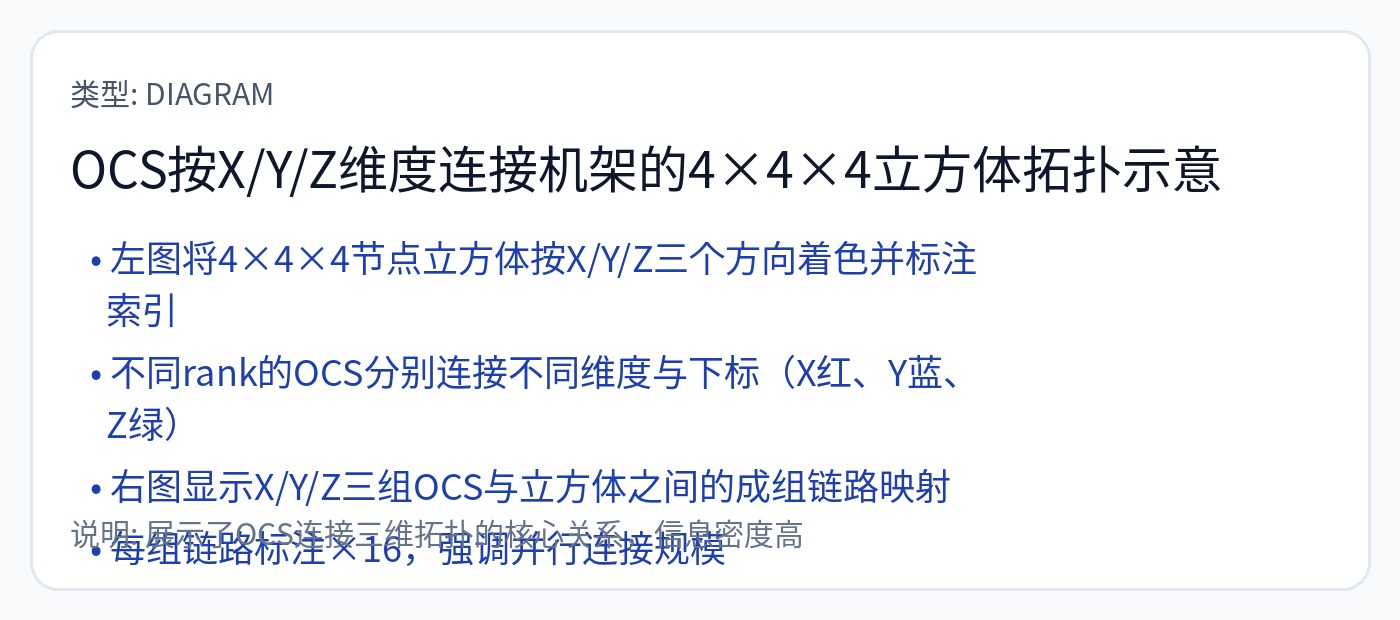
这比 Nvidia 的策略更加可靠且更具成本效益,但使编译器的灵活性大大降低。程序员需要考虑网络的不均匀性,包括延迟和带宽不对称。
最后,未来 TPU 将使用蜻蜓拓扑。 Broadcom 制造的真正 TPU。
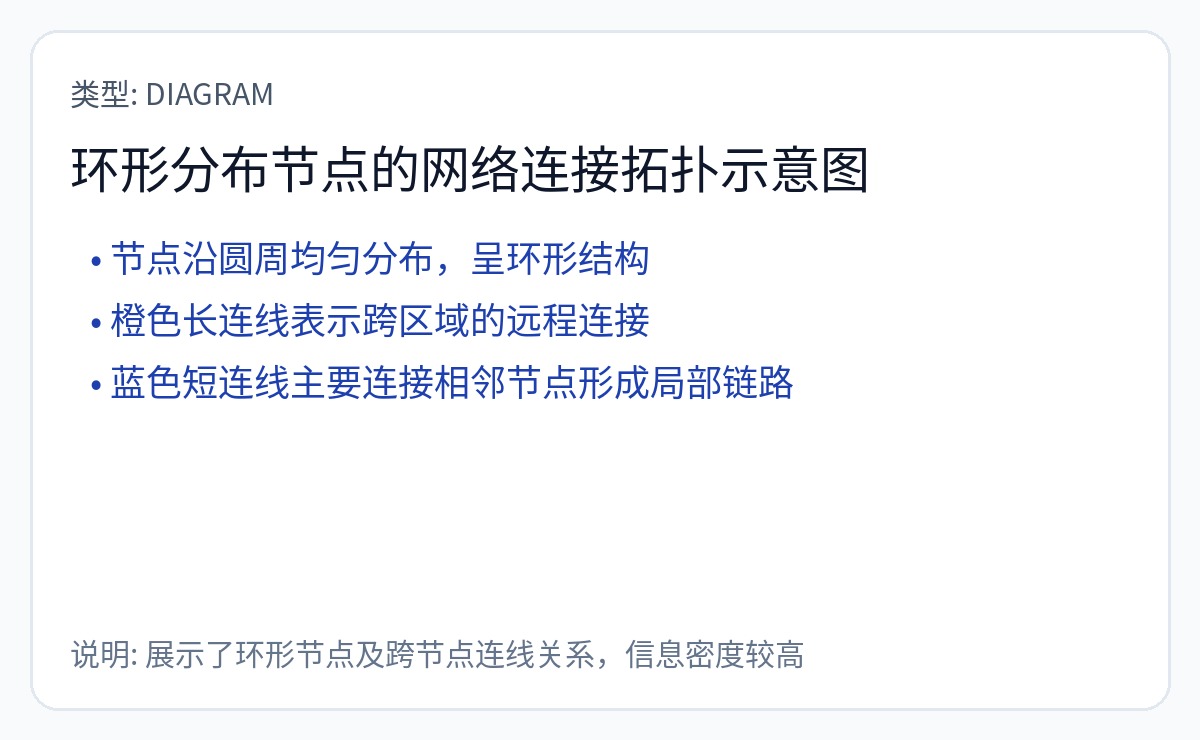
https://research.google.com/pubs/archive/34926.pdf
阿布茨先生还会多次出现。

[2] 普通架构
这里是给懒人的总结表。
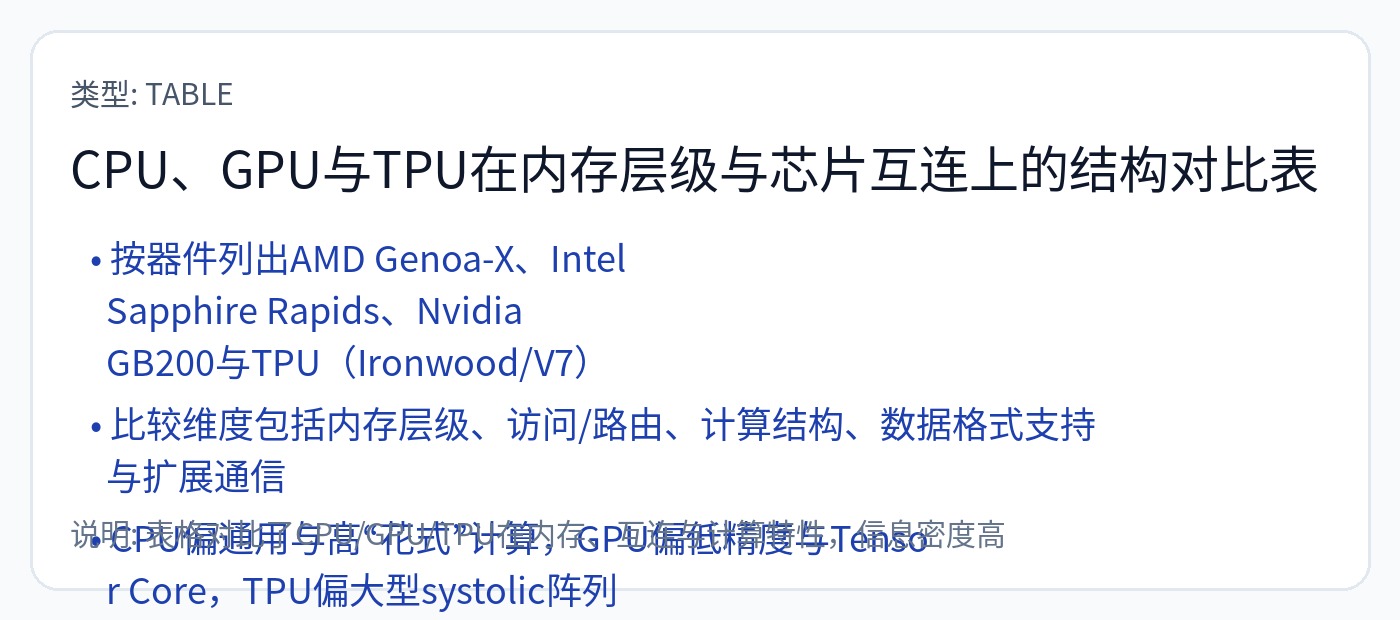
<全部更新表>
[2.a] CPU(AMD Genoa-X)
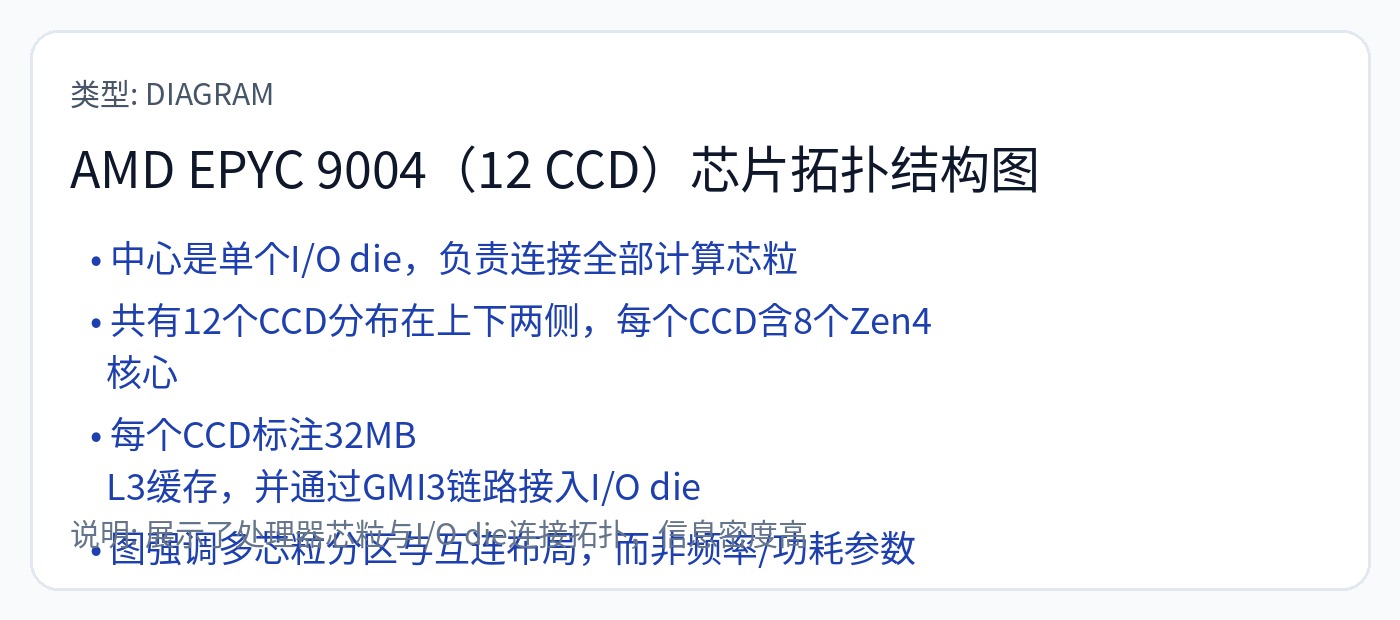

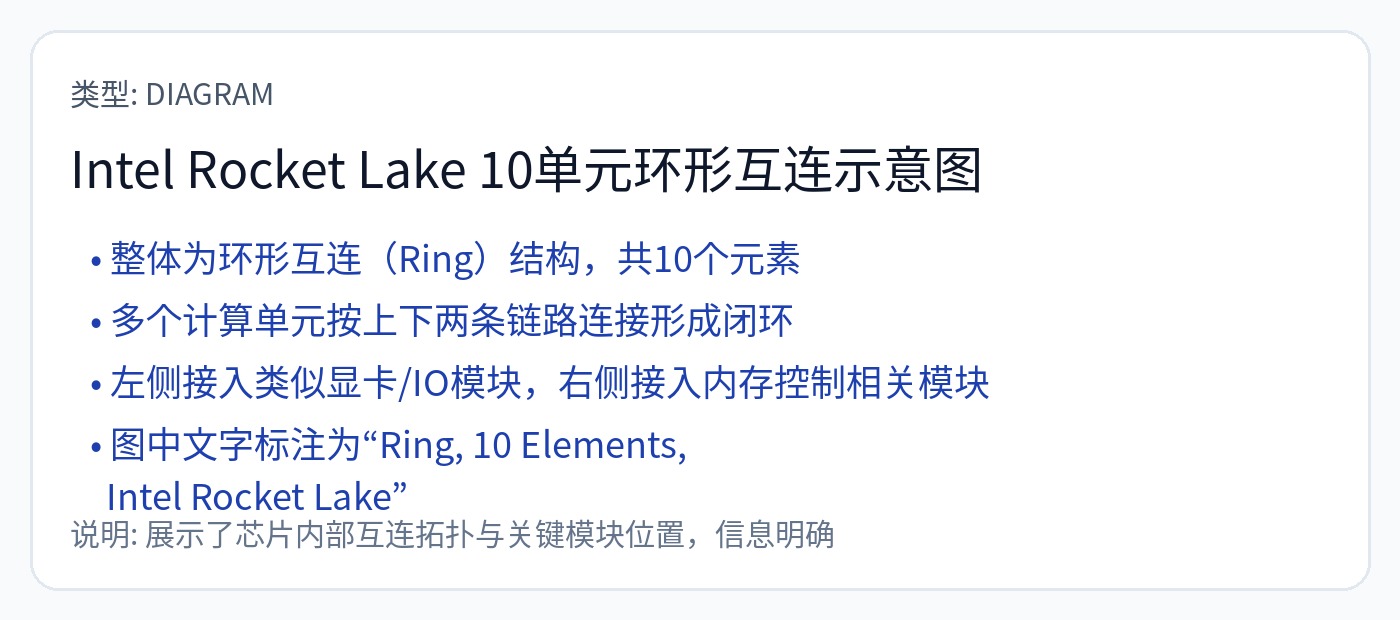
AMD 在其 NoC 中采用嵌套环架构。每个 CCD(CPU 核心芯片)都是一个连接到 I/O 芯片的环。所有内存接口也连接到 I/O 芯片。
特殊 SKU(-X 系列)将额外的 SRAM 芯片混合粘合到 CCD 芯片上。
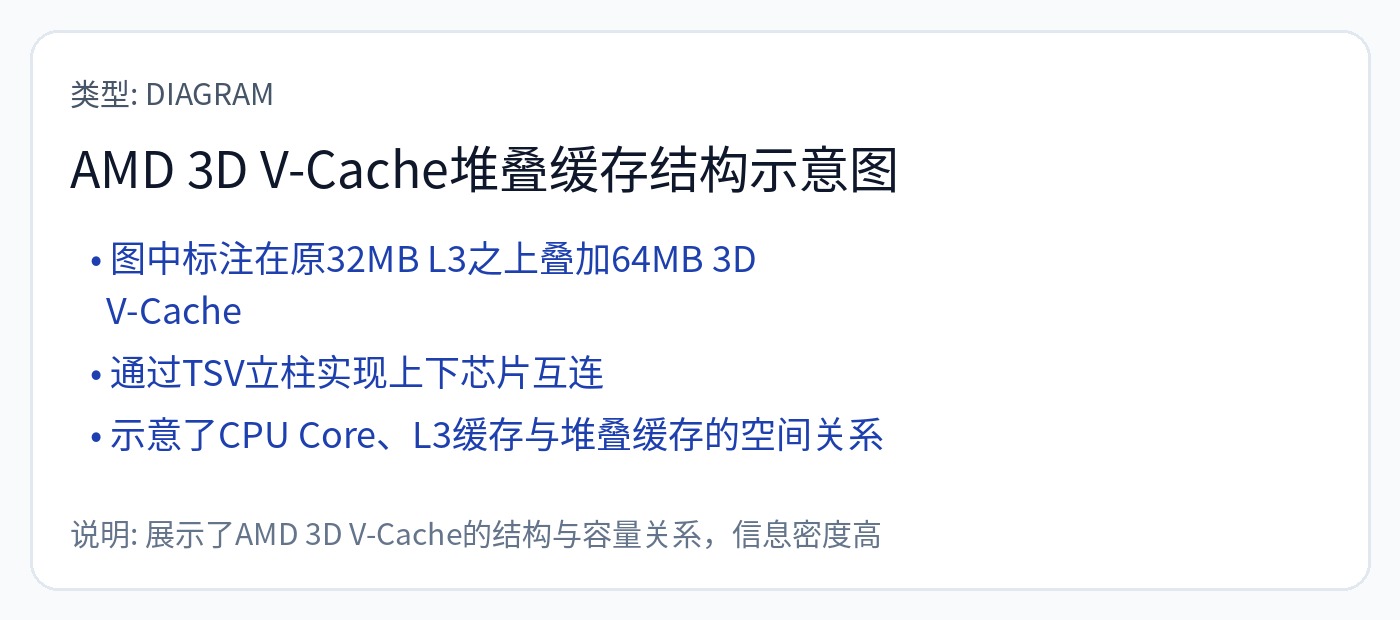

该策略会导致 L3 的大量高速缓存 SRAM 耗尽。由于物理位置的原因,L3 延迟受到一定程度的影响。
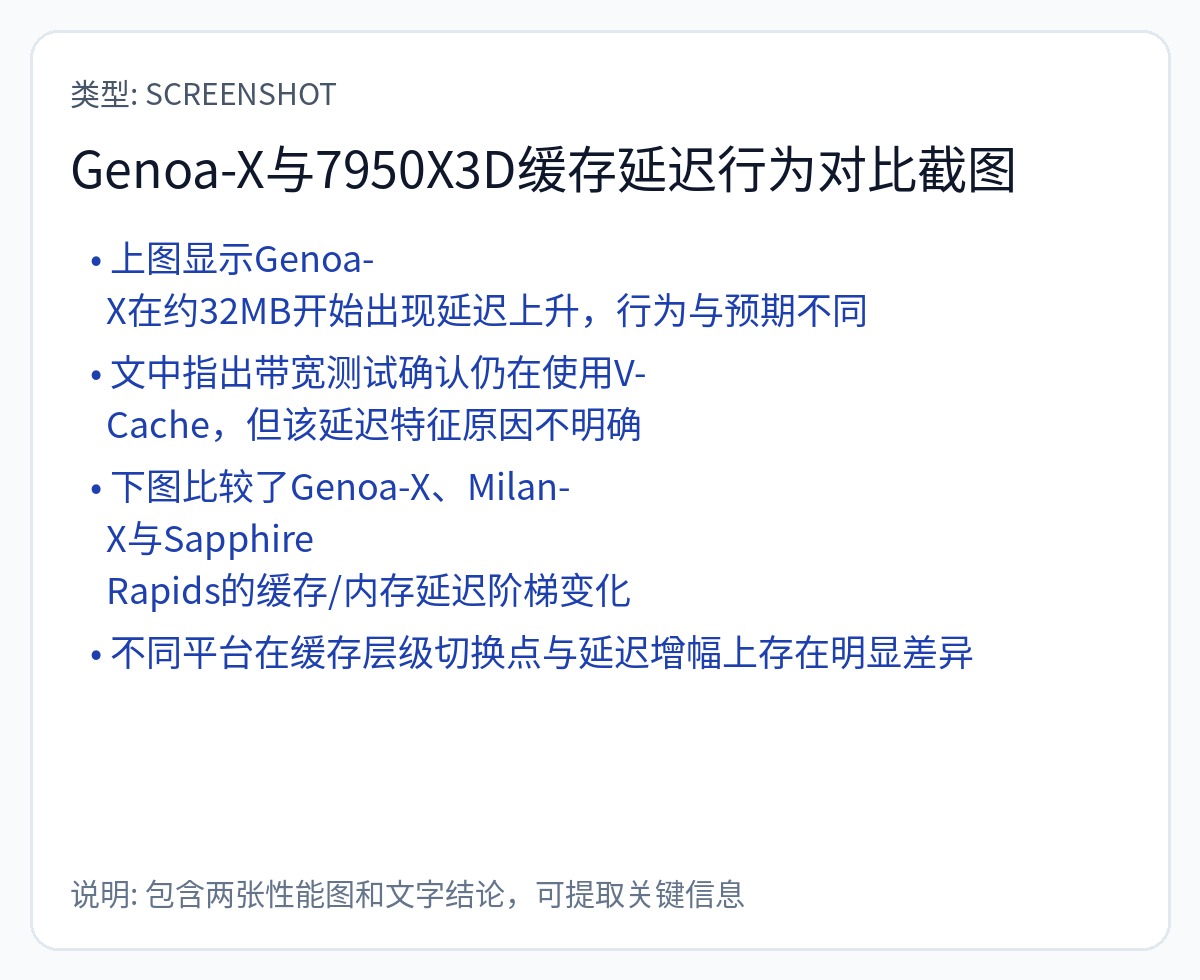
我想确保没有人错过的关键点如下:
AMD -X SKU 扩展了高速缓存 SRAM。特别是L3缓存。
尽管 AMD 公开声称没有延迟影响,但 Chips 和 Cheese 的独立测试显示了一些轻微/奇怪的性能损失。
在计算之上堆叠 SRAM 非常困难。 AMD 选择仅将 SRAM 芯片堆叠在现有 SRAM 之上来避免此问题。请注意 CPU 内核本身上方的两个“结构”(垫片)芯片。
AMD 做出的设计选择对于理解 Groq 和 D-Matrix 路线图具有指导意义。

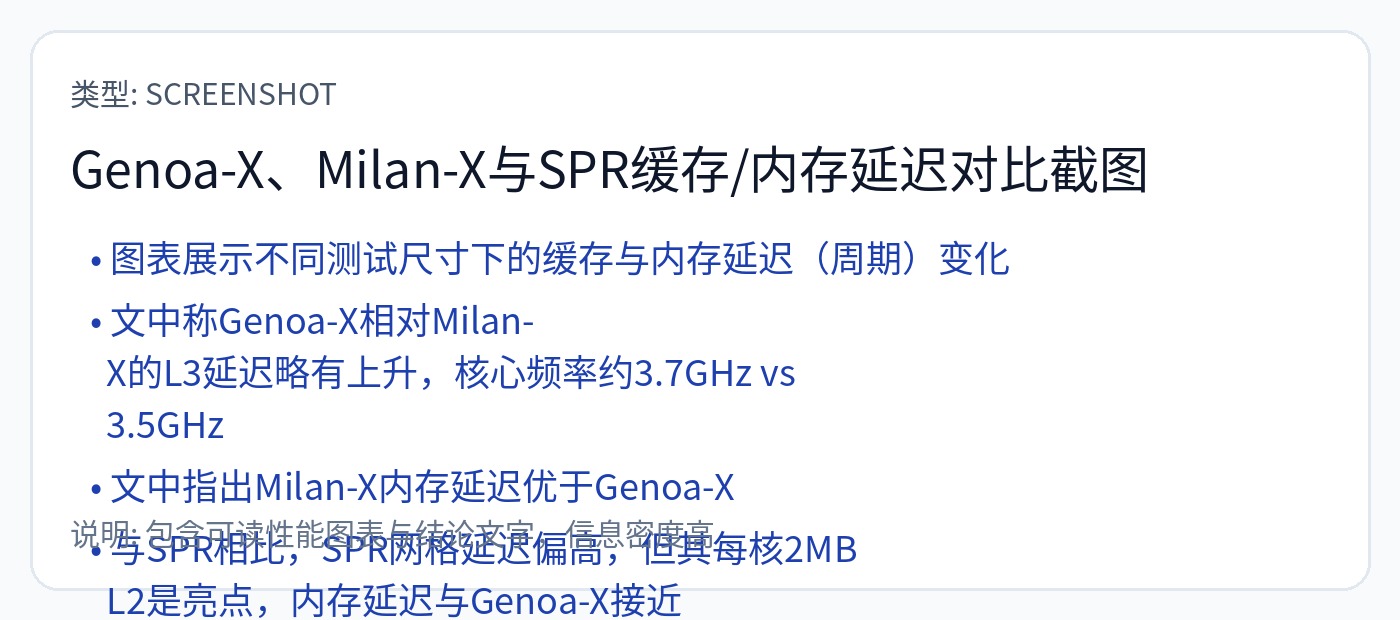
[2.b] CPU(英特尔 Saphire Rapids)
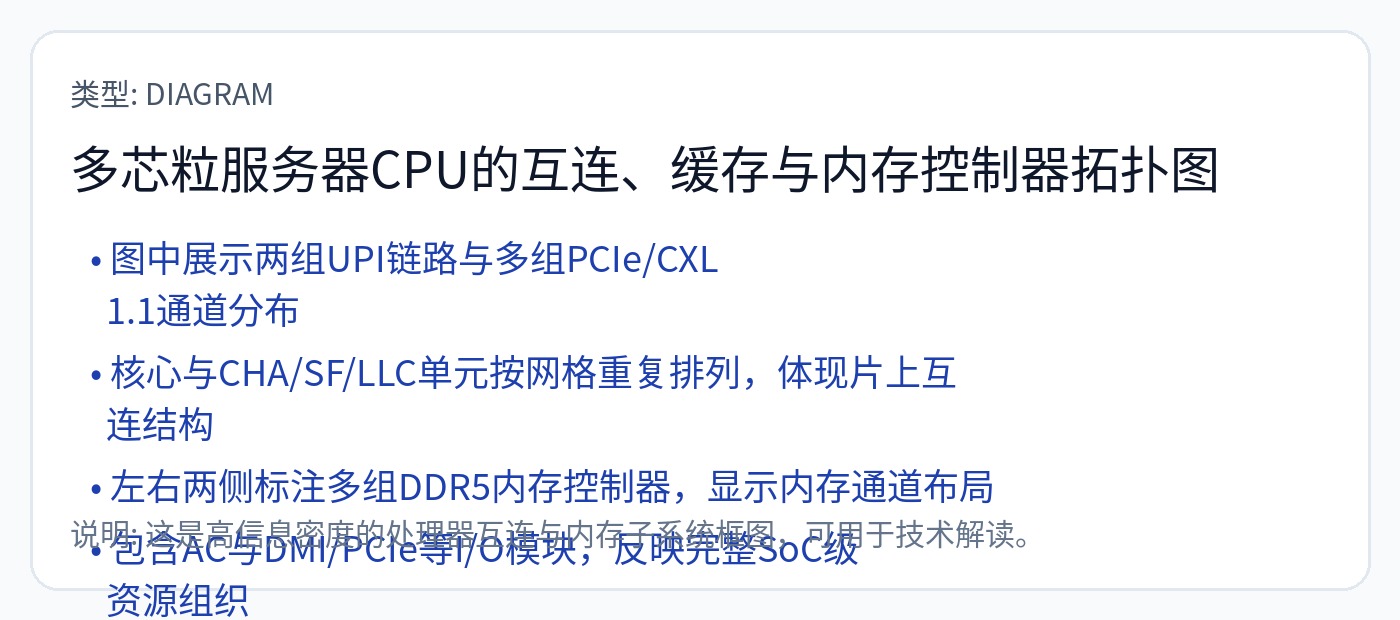
Intel Saphire Rapids 有一个更传统的网状 NoC。请记住,DRAM 数据需要多次跳跃才能到达中间的核心。另请注意,某些片上加速器(小型 ASIC)(例如 QAT 和 DSA)位于其自己的块中,并具有专用的网格节点。
高速缓存 (SRAM) 通过紫色块展开。
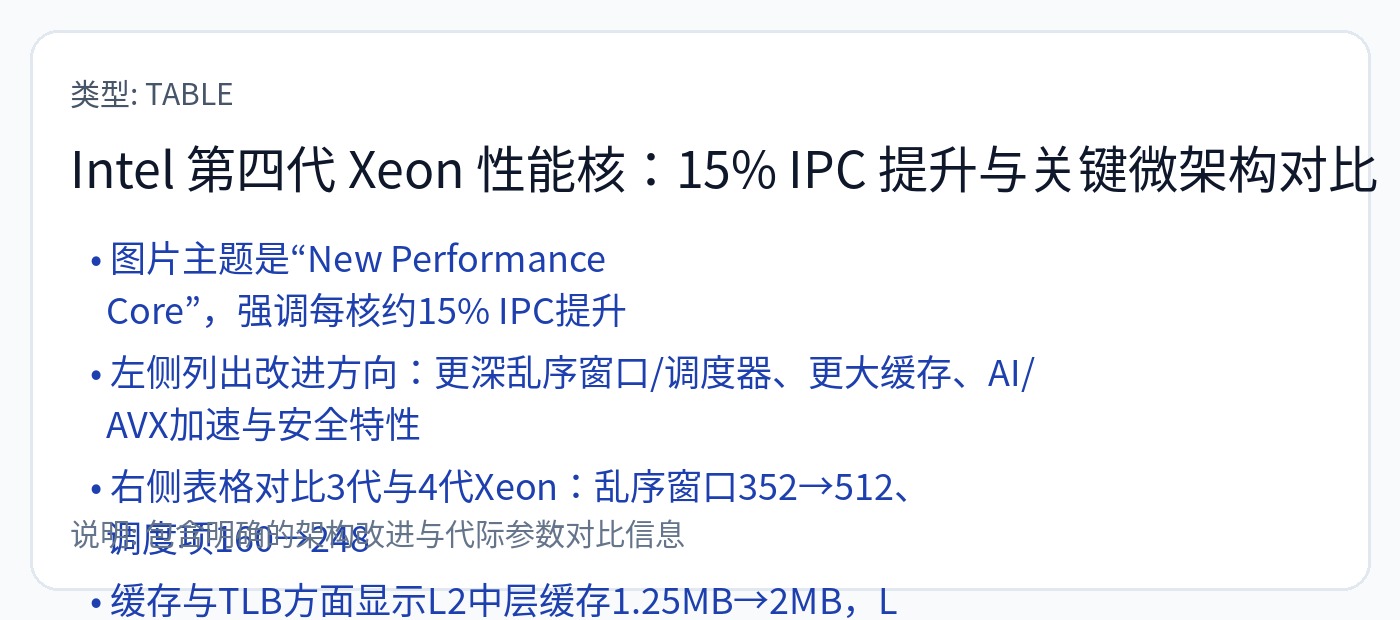
请注意,AMD 的每个 8 核 Genoa CCD 拥有 32 MB 的大型共享 L3 缓存,而 Intel 选择以 1.875 MB/核心块的形式将 L3 缓存设为每个核心专用。
要点:
高速缓存/SRAM 设计需要进行许多权衡。
更大的共享缓存意味着更多的延迟,但所有计算核心都可以使用相同的内存。
SRAM 块越大并不总是越好。
很多细微差别取决于核心微架构和 NoC 设计。
[2.c] GPU(Nvidia GB300 // Blackwell Ultra)
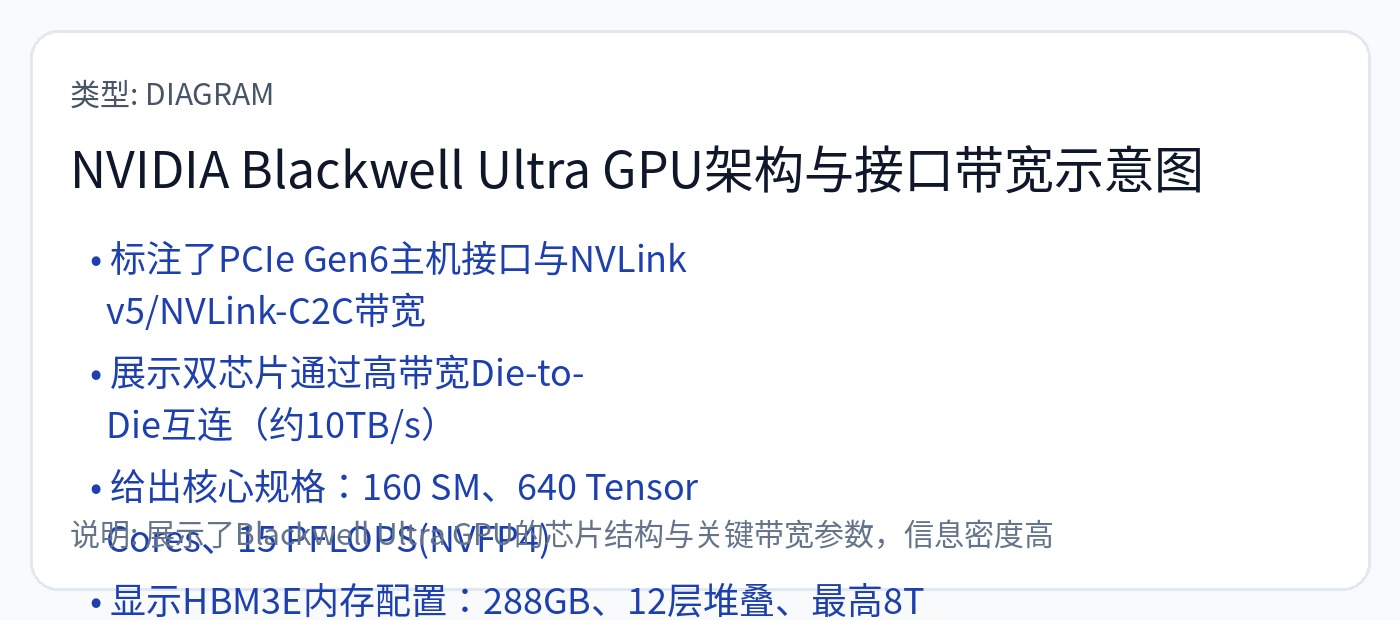
请注意两个 GPU 集群之间的大型共享 L2 缓存。 D2D 是时钟转发的。

Warp 调度程序每个时钟 32 个线程。这是 GPU 的历史 (SIMD) 主干。张量核心可以通过多种方式进行交互。 SA 的报道范围很广,所以请阅读一下。
Nvidia 在 GPC 中使用网状 NoC,而千兆线程引擎则是交叉开关。换句话说,网格连接到横杆上。
[2.d] TPU(铁木 // V7)
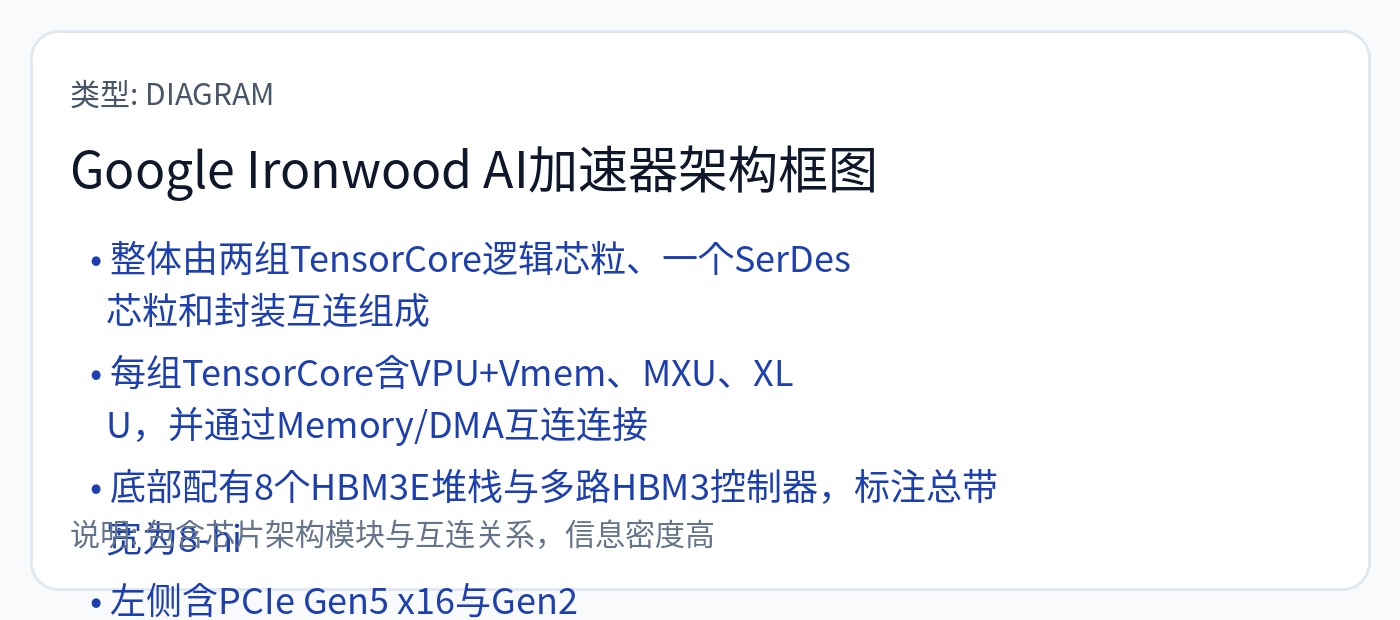
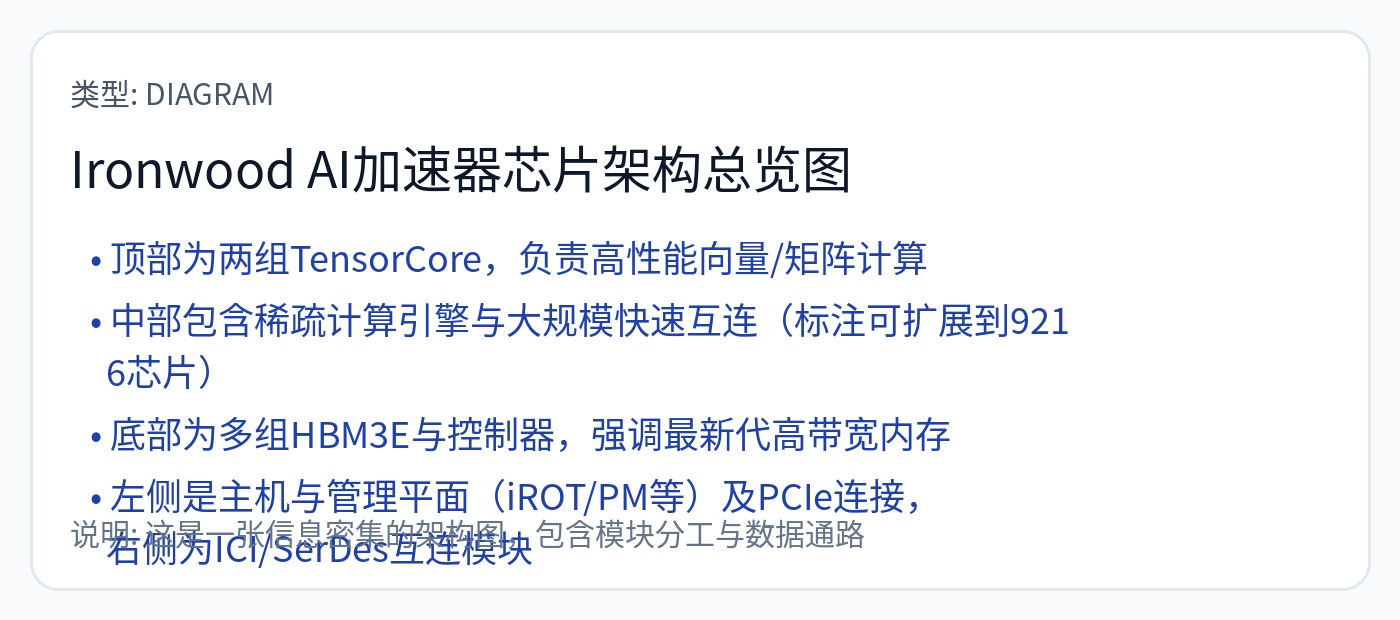
Google 使用 Crossbar NoC,并在片上集成了路由(黄色框)。这意味着没有相当于用于扩展的 NVLink 开关的开关。
计算围绕 256x256 脉动阵列构建,作为矩阵乘法的主要计算引擎。控制由 8 宽 VLIW 内核处理。您可以将 8 宽 VLIW 视为控制器。
编译器必须提前生成指令包。
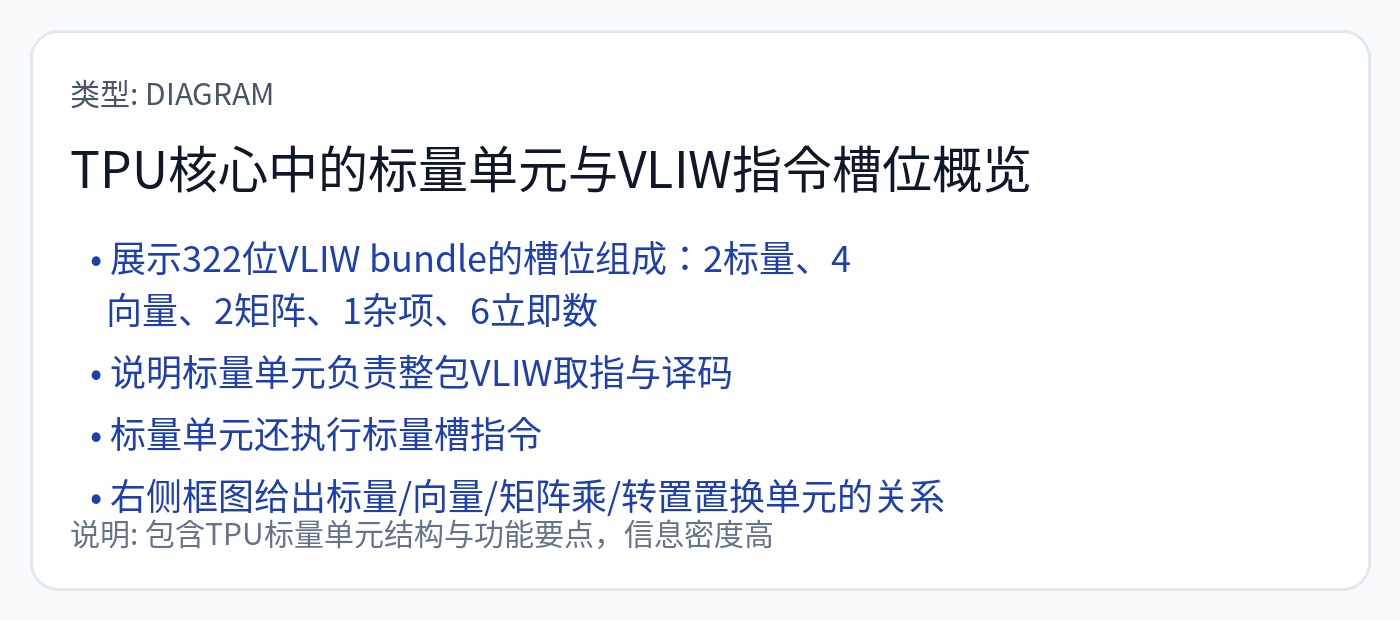
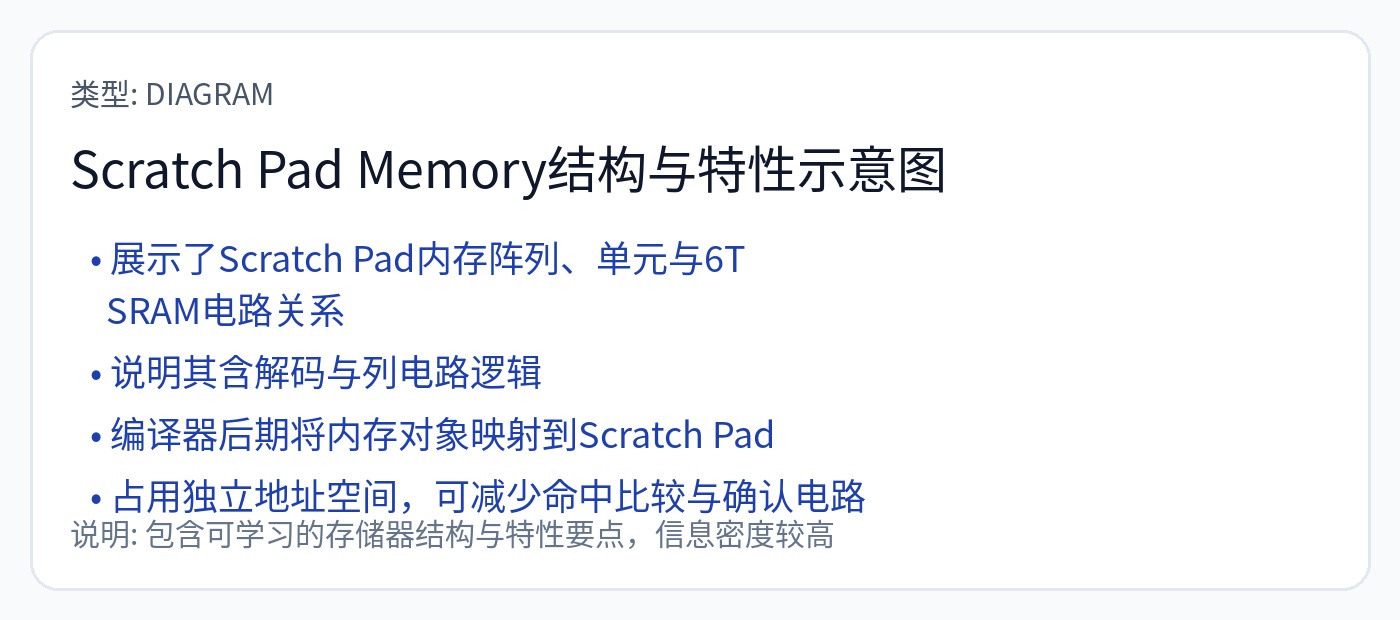
理解 TPU 上的 SRAM 不是缓存非常重要。
它是一个暂存器,用于为脉动阵列提供数据。
https://en.wikipedia.org/wiki/Systolic_array
脉动数组是数据流计算结构。
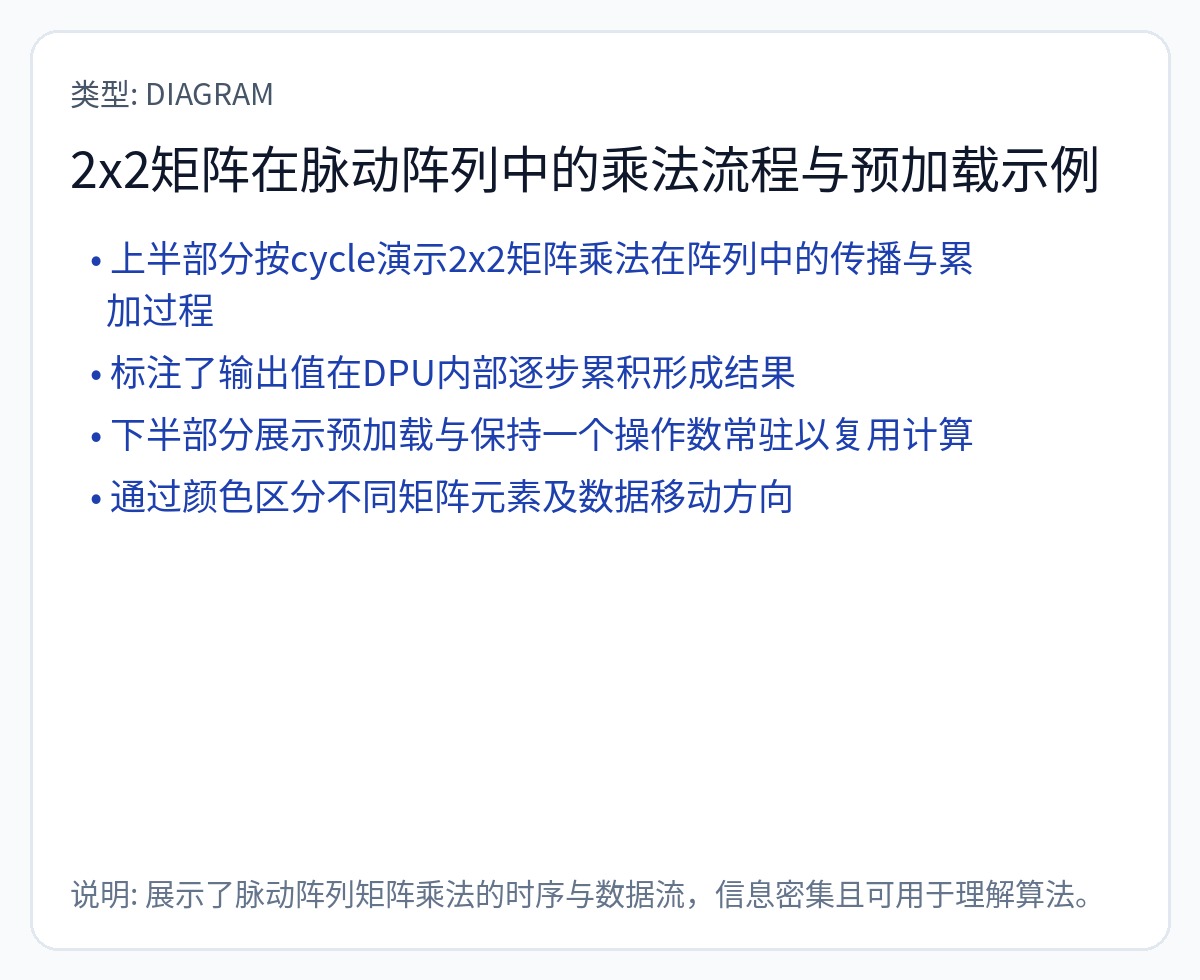
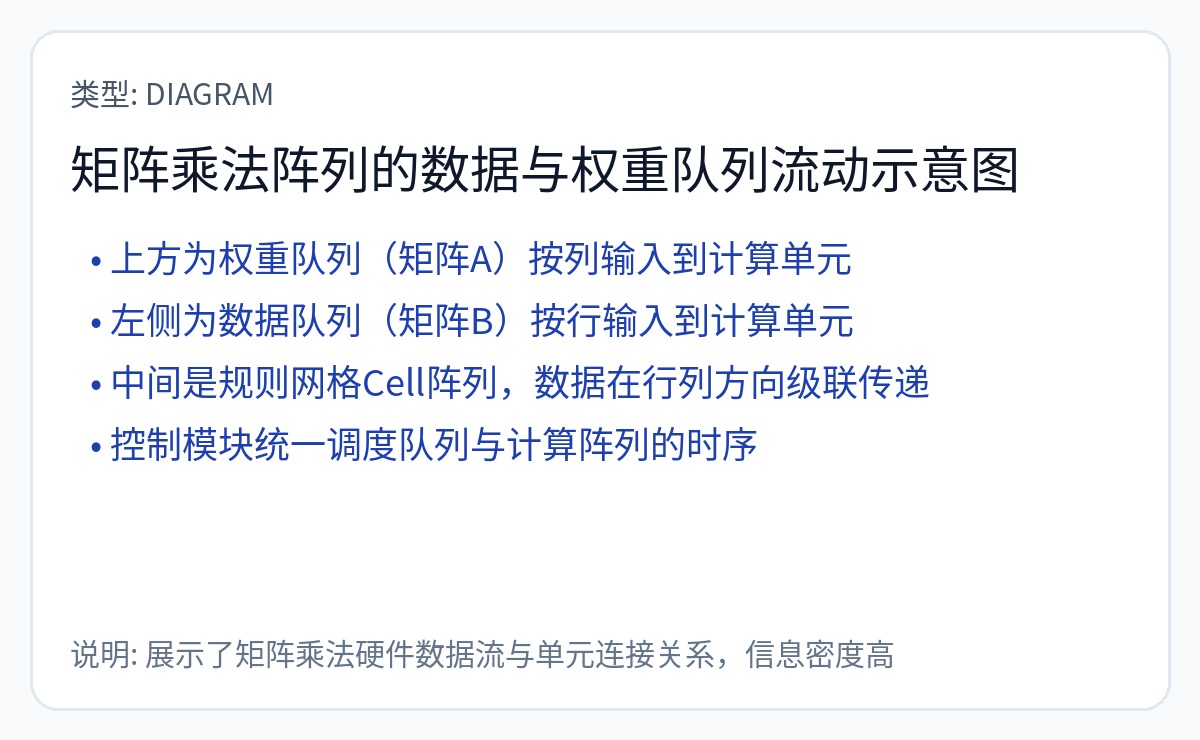
大多数人工智能硬件初创公司都使用不同大小和配置的脉动阵列。谷歌自己已经改变了各代 TPU 脉动阵列的大小。确定加速器设计的脉动阵列的尺寸和形状非常复杂。
[2.e] Tentorrent
<全部>
[2.f] 正电子
<全部>
[3] 异常架构<全部>
<全部>
[3.a] D 矩阵 <todo>
<全部>
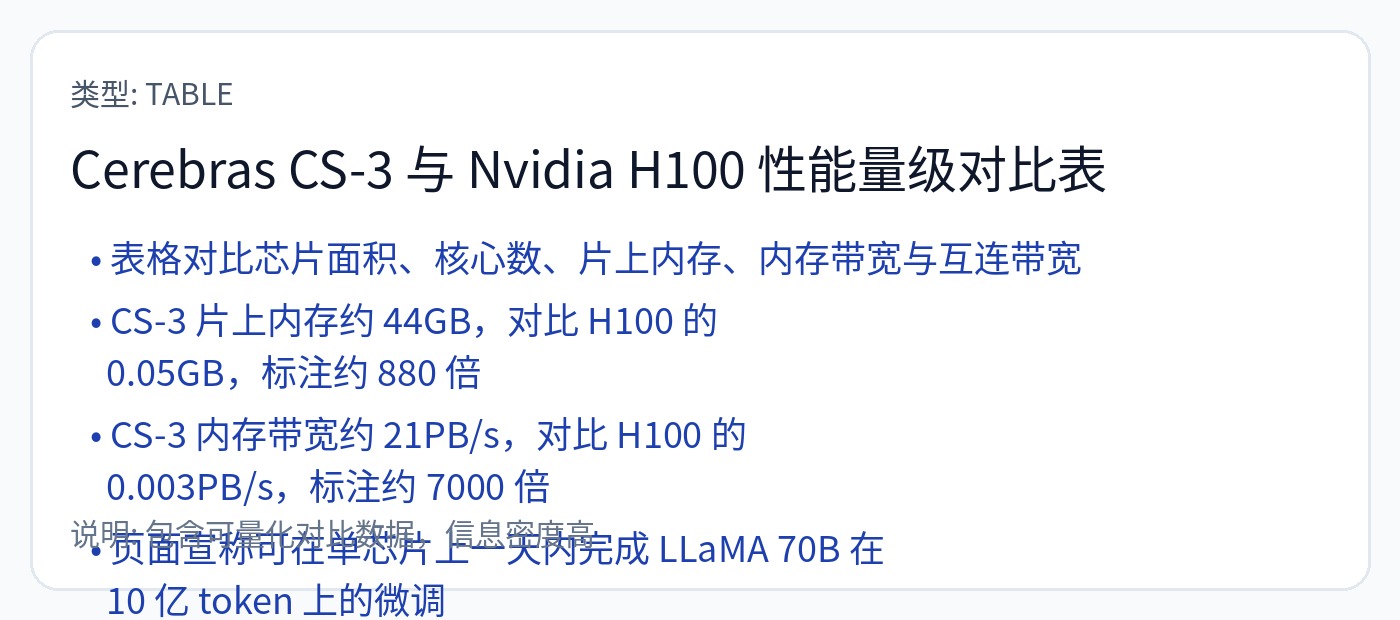
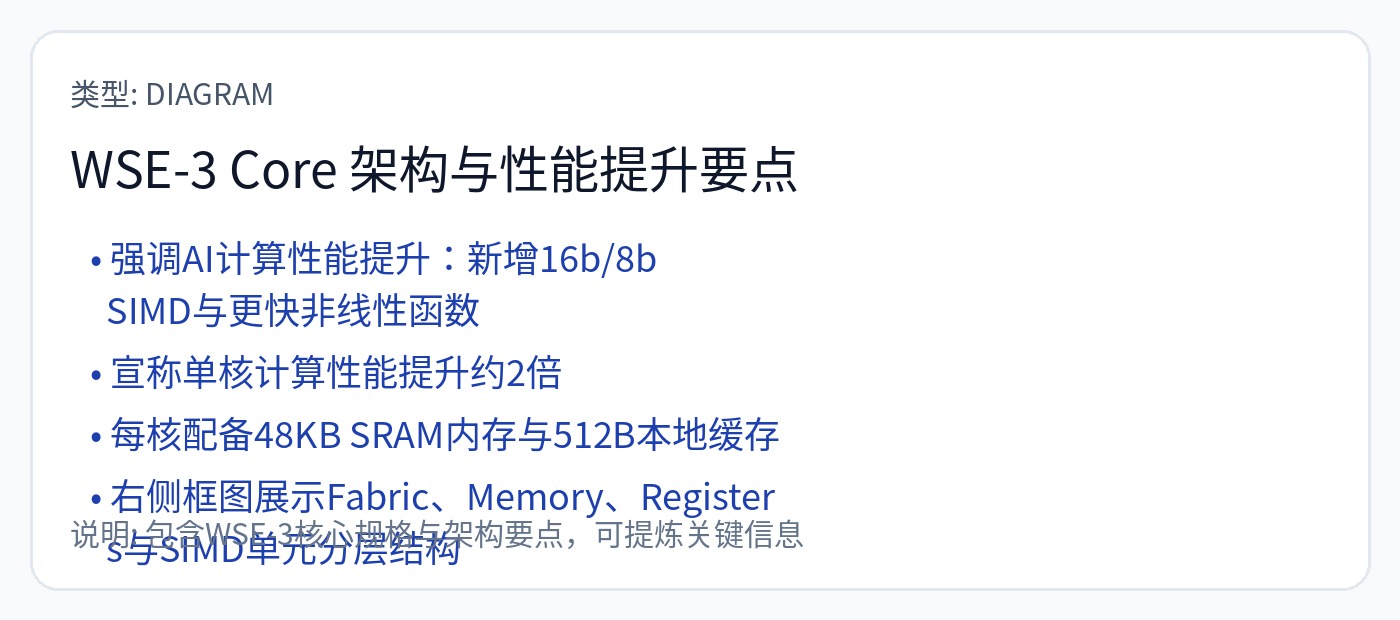
[3.b] 大脑<全部>
<全部>
[3.c] SambaNova <todo>
<全部>
[3.d] 蚀刻<todo>
<全部>
[3.e]MatX <todo>
<全部>
[4]塔拉斯:非常异常<todo>
<全部>
[5] Groq:疯狂和精神错乱
由于几个关键原因,Groq 在行业内的两极分化非常严重。
任何对计算机体系结构有基本了解的人都会立即理解他们所创造的可憎事物。
宣扬了 144 宽 VLIW 的所有神奇优势,但没有解决任何缺点。
使用基于垃圾 GloFo 14 纳米工艺的 6 年老旧芯片建立了落后的“云业务”。
在胡说八道的云业务中生成的每个代币都在损失金钱。
人们尝试过的最大 VLIW 包大小是 8。这些退化的宽度为 144。
一位特别令人讨厌的投资者。
我与一位时尚的 Groq 员工进行了多次口头争论,他反复声称该架构不是 144 宽 VLIW。
“我们创造了一些不同的东西。”
废话
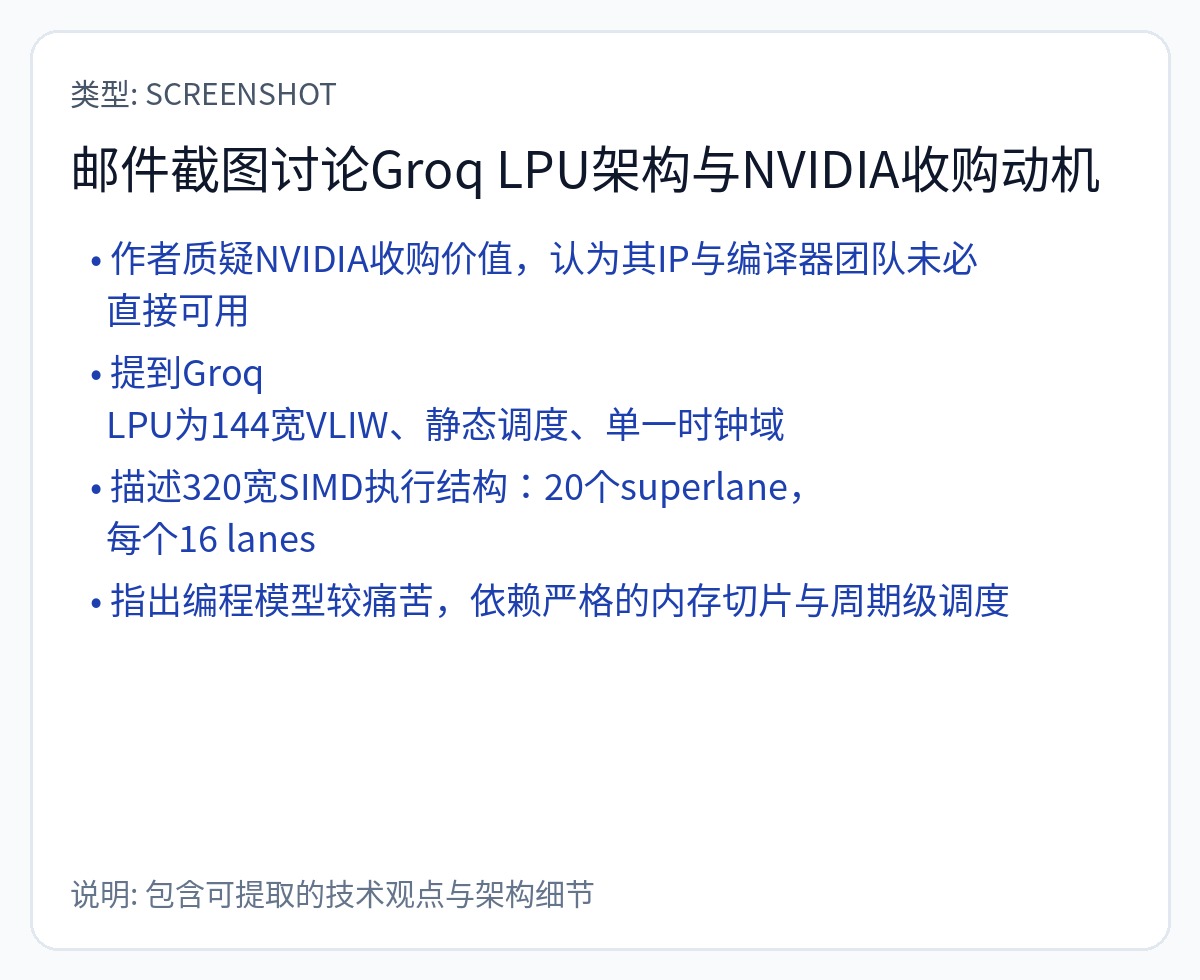
使用过 Groq Cloud 的工程师都知道该芯片是 144 宽的 VLIW,需要编译器进行周期粒度的静态调度。
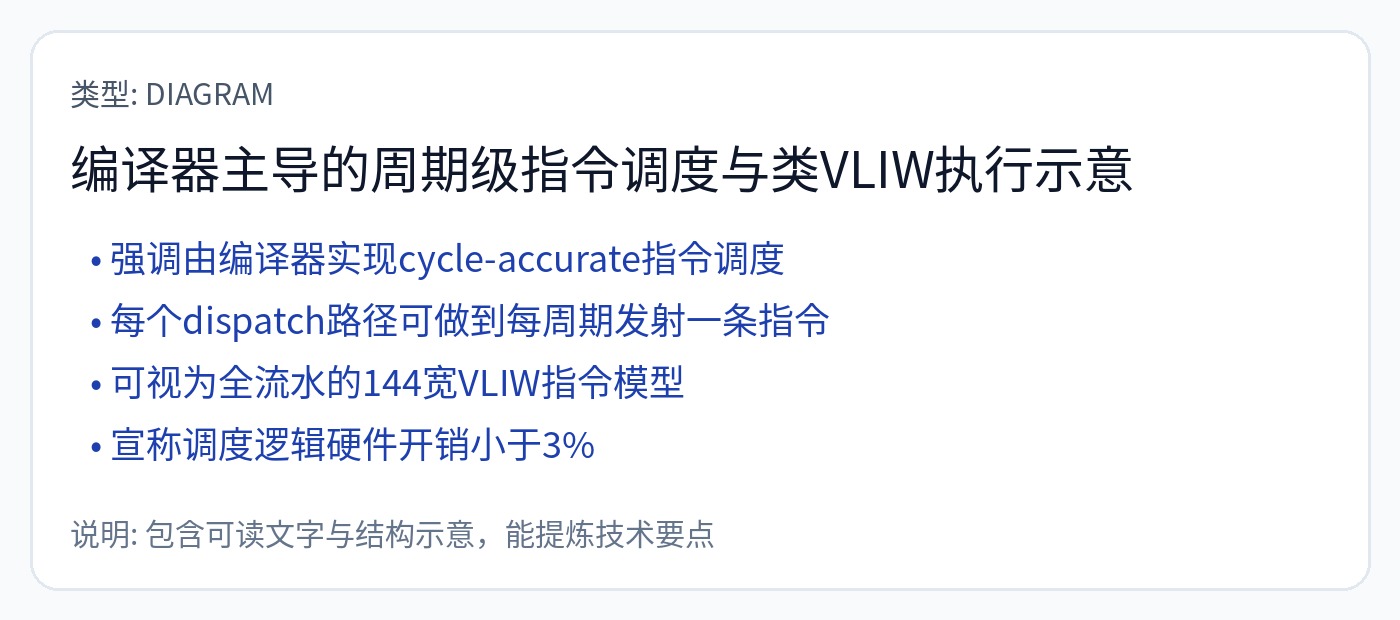
Groq 在 Hot Chips 2022 上的公开演讲明确承认该架构可以被视为 144 宽 VLIW。
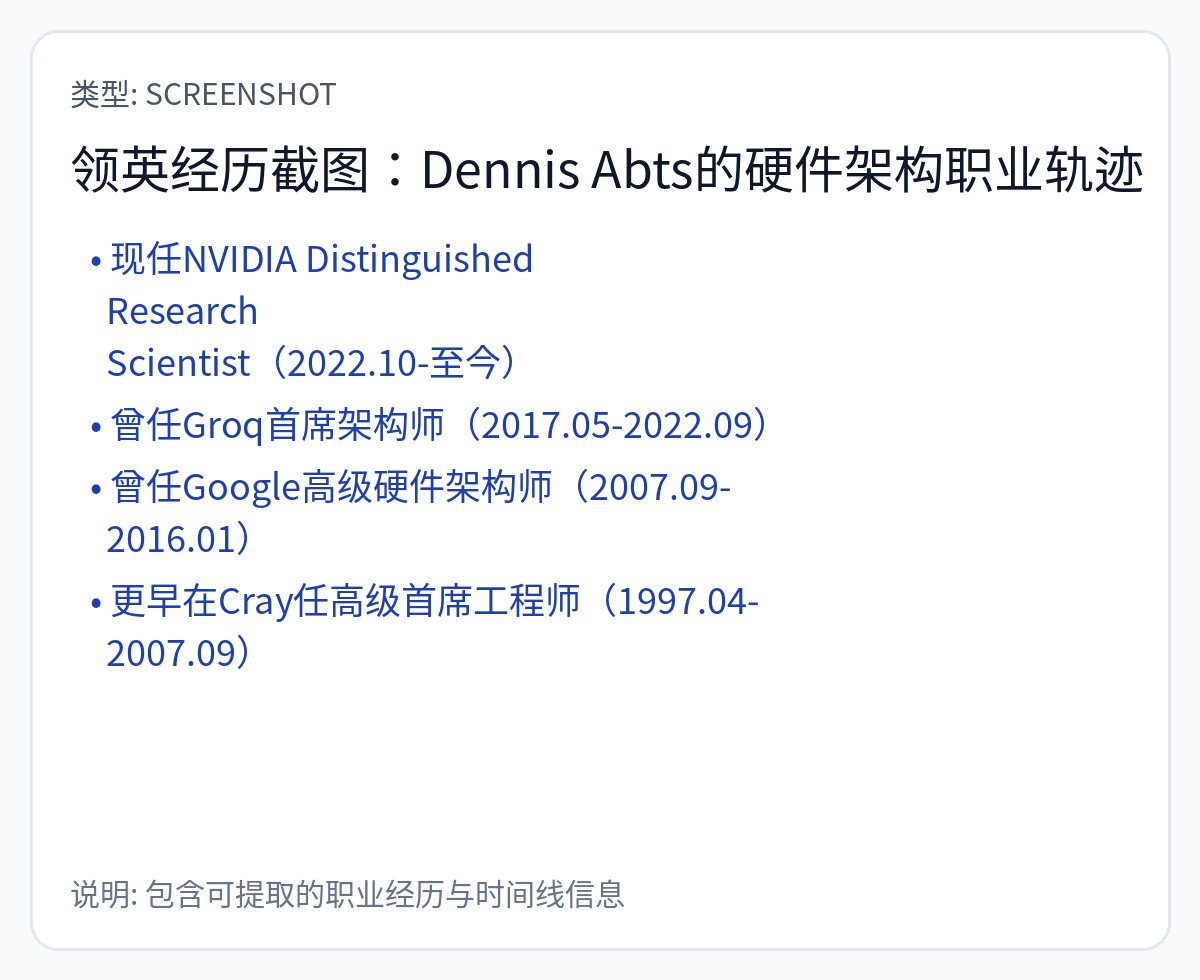
Dennis Abts,Groq 的 CHEIF 架构师,在 Hot Chips 上亮相,承认使用 144 宽 VLIW,一个月后正式加入 Nvidia。
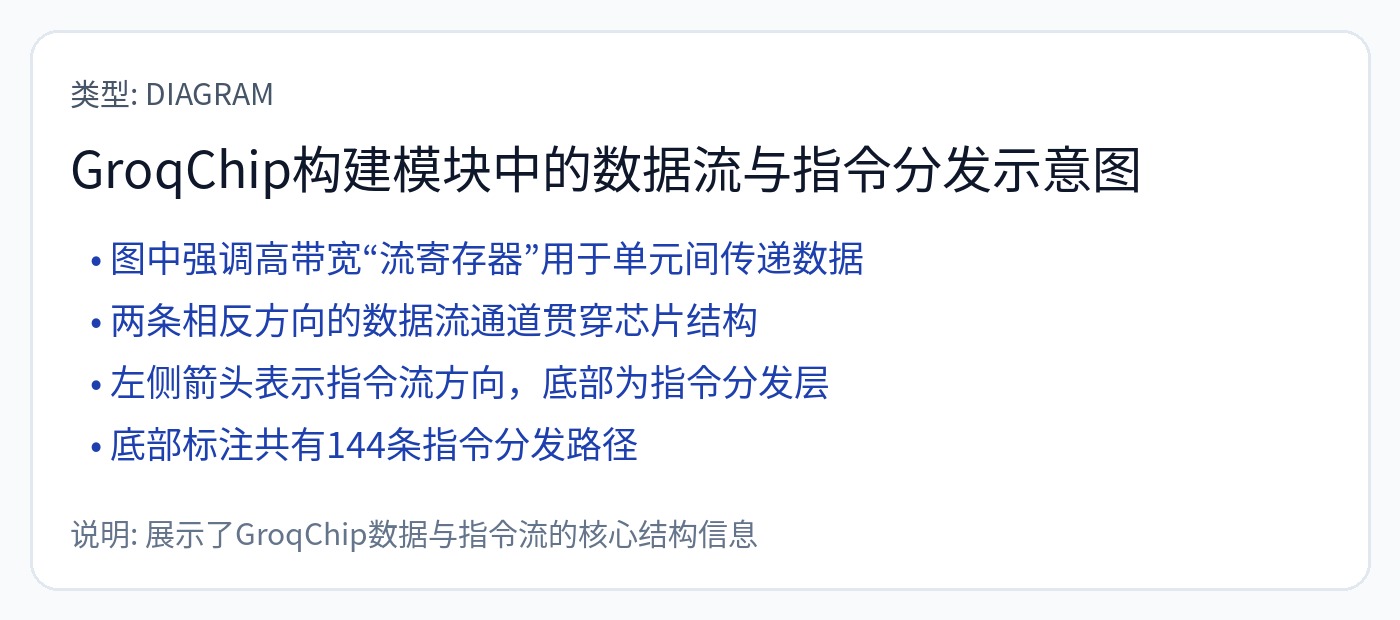
Groq 是一种数据流架构,但以最疯狂、最令人反感、最疯狂的方式出现。
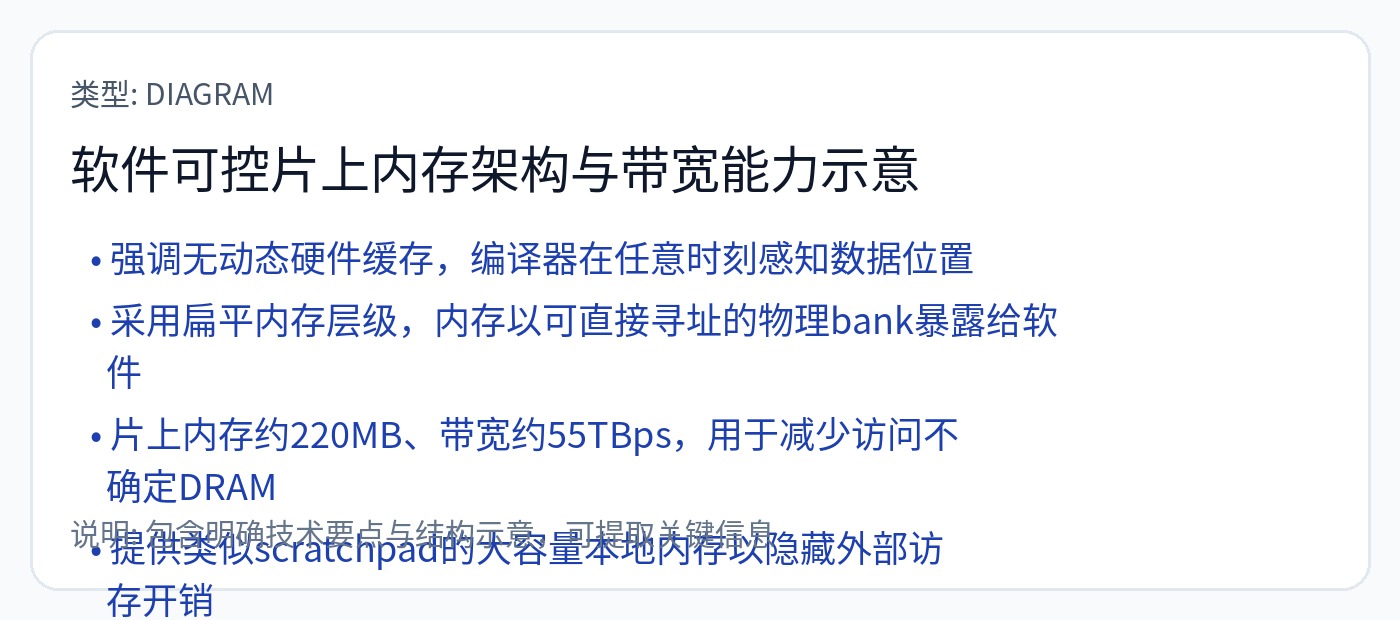
暂存器 SRAM。编译器必须提前循环准确地安排一切。
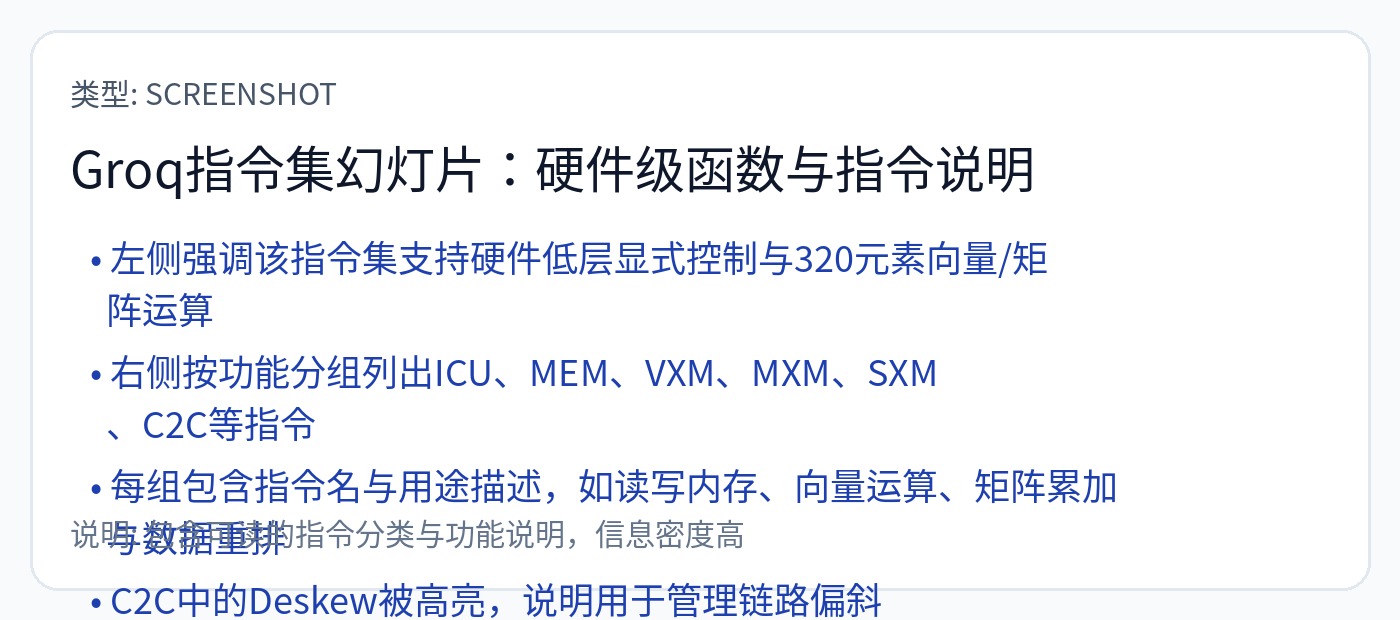
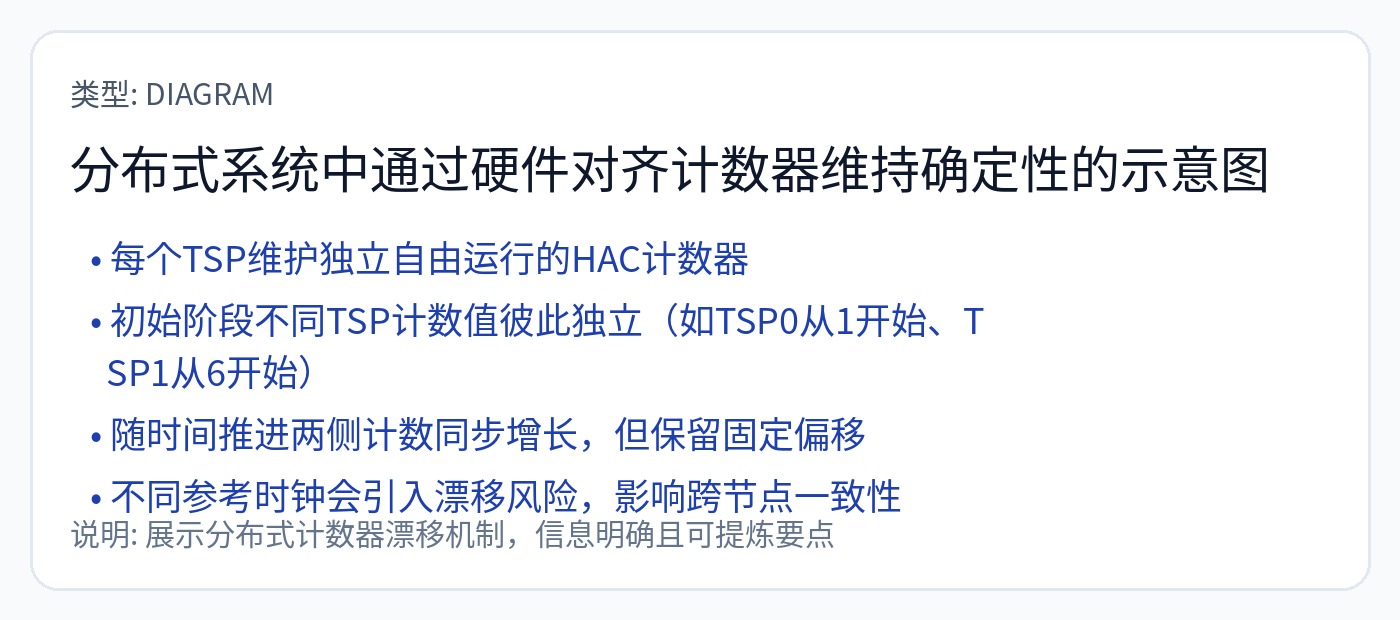
他们必须尽可能地同步所有芯片。每个机架上每个服务器中的每个芯片。
一旦出现最轻微的同步问题,这个编译器就会起火。
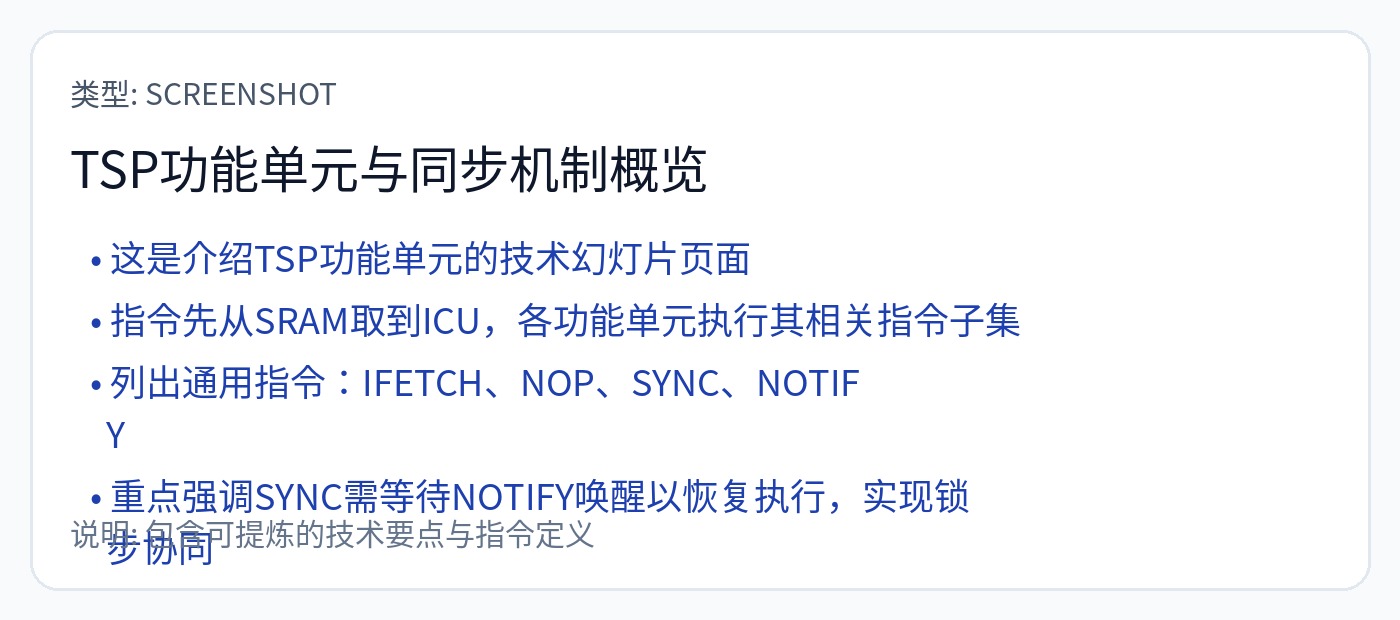
如果同步不好,他们就必须停止所有计算。
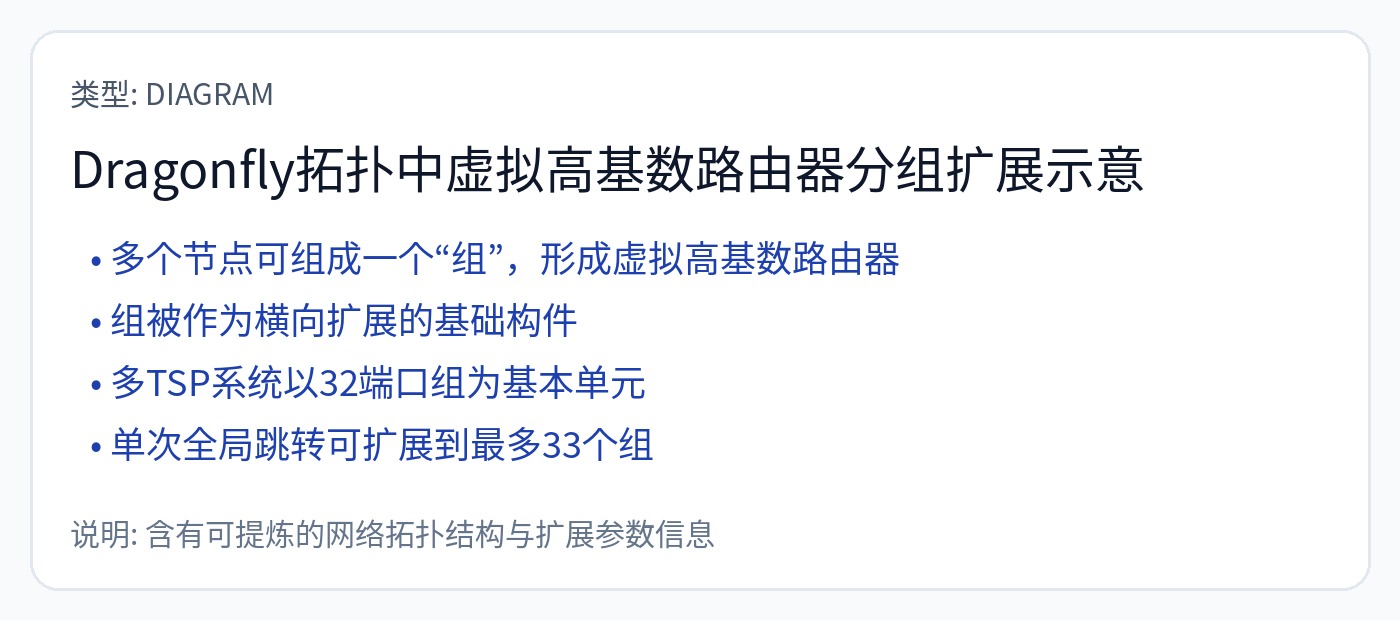
还记得阿布茨先生再次出现的情景吗?是的,他在谷歌发明了 Dragonfly。
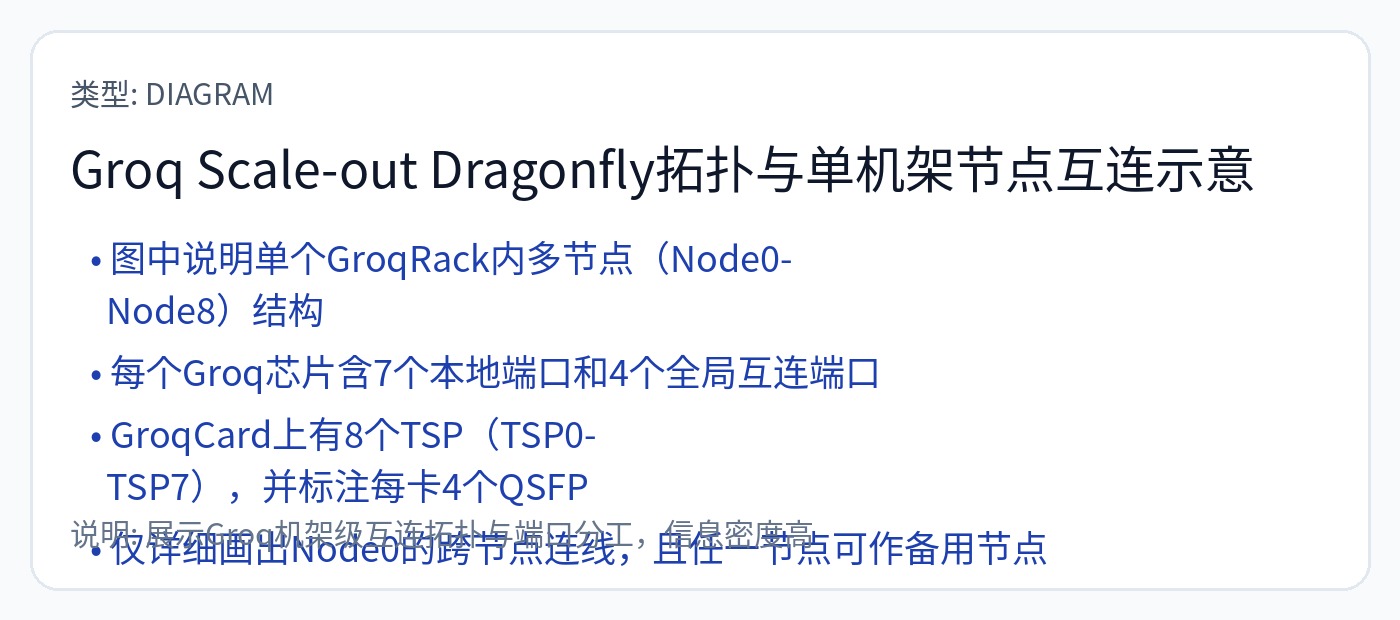
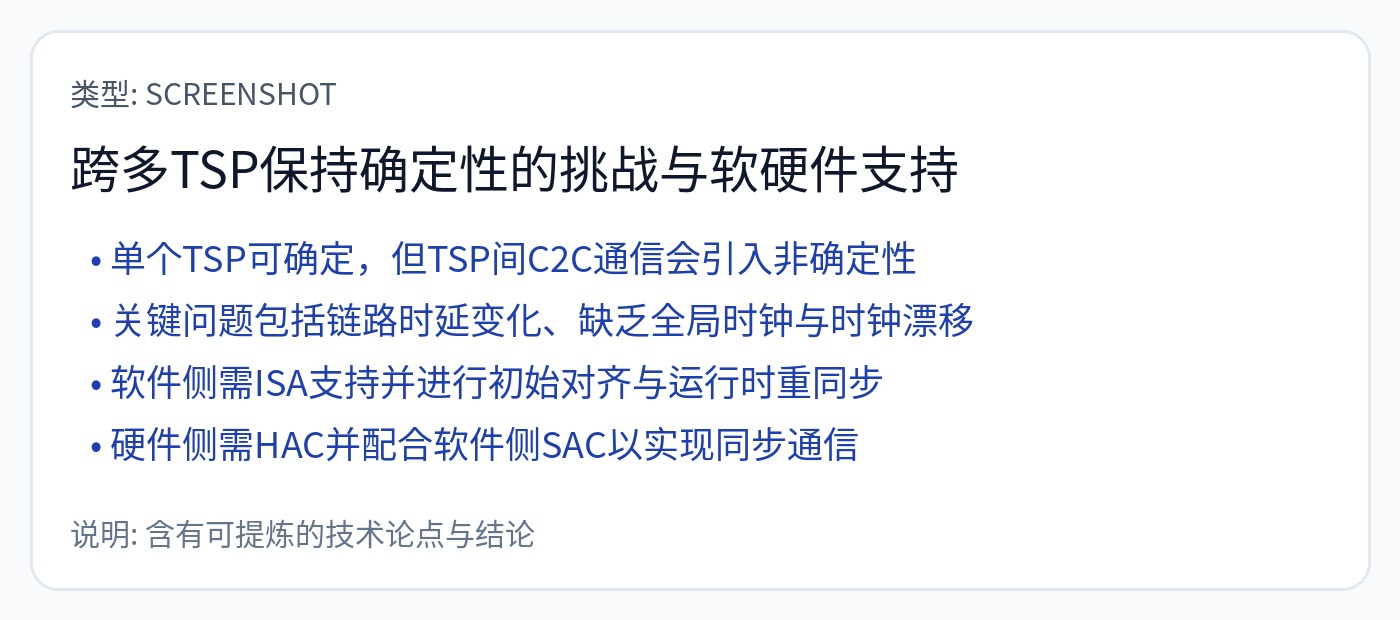
我已经阅读了他们关于同步工作原理的专利。有很多更好的方法可以做到这一点。下一节将详细介绍这一点。
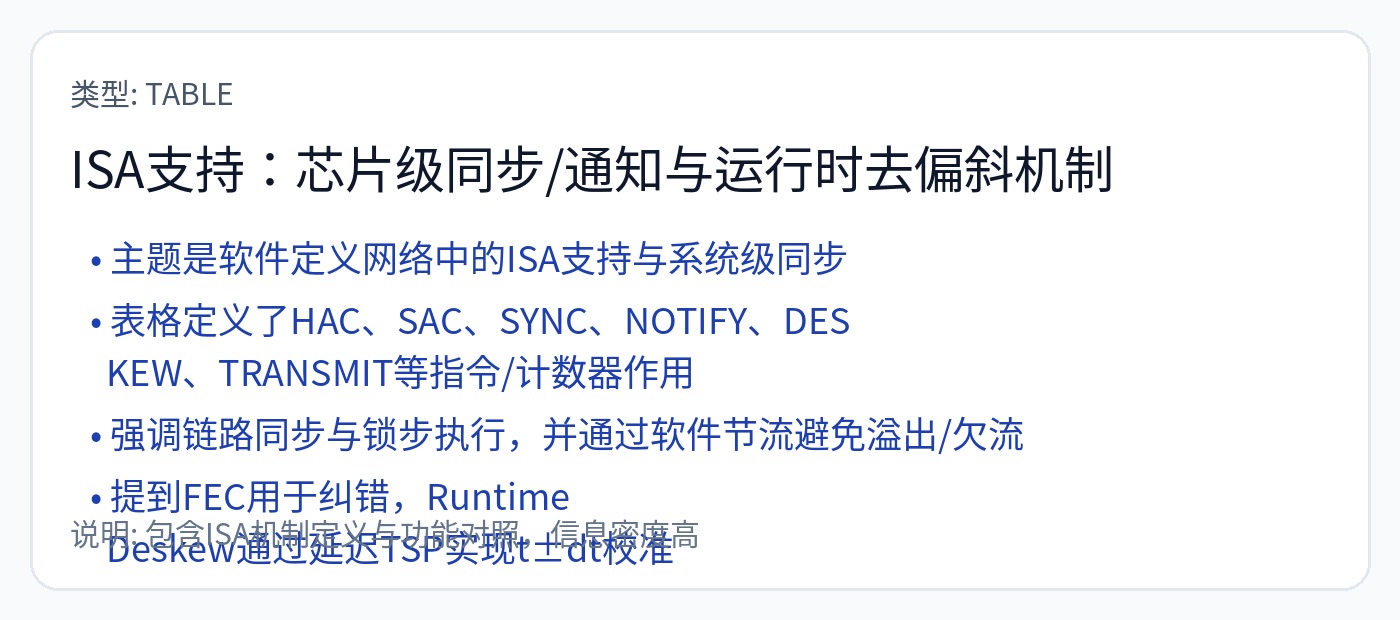
如果偏差随着时间的推移而变化(确实如此!),执行就会按设计停止。
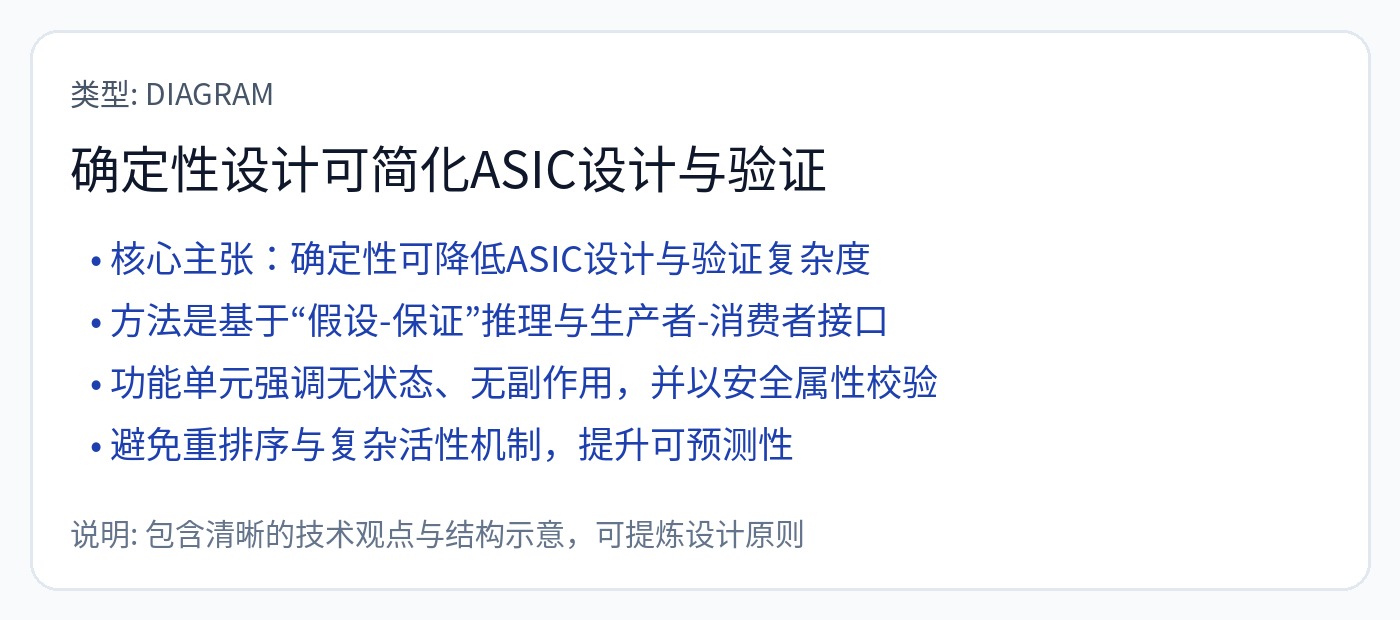
这是真实的。 Groq 架构给编译器带来了如此巨大的负担,一个由 10 名有能力的数字设计师组成的团队可以在 6 个月内复制设计。
该芯片的设计非常简单。复杂性负担并没有消失!复杂性转向计算机历史上最地狱般的编译器。
以下是 Groq 专利的一些片段。
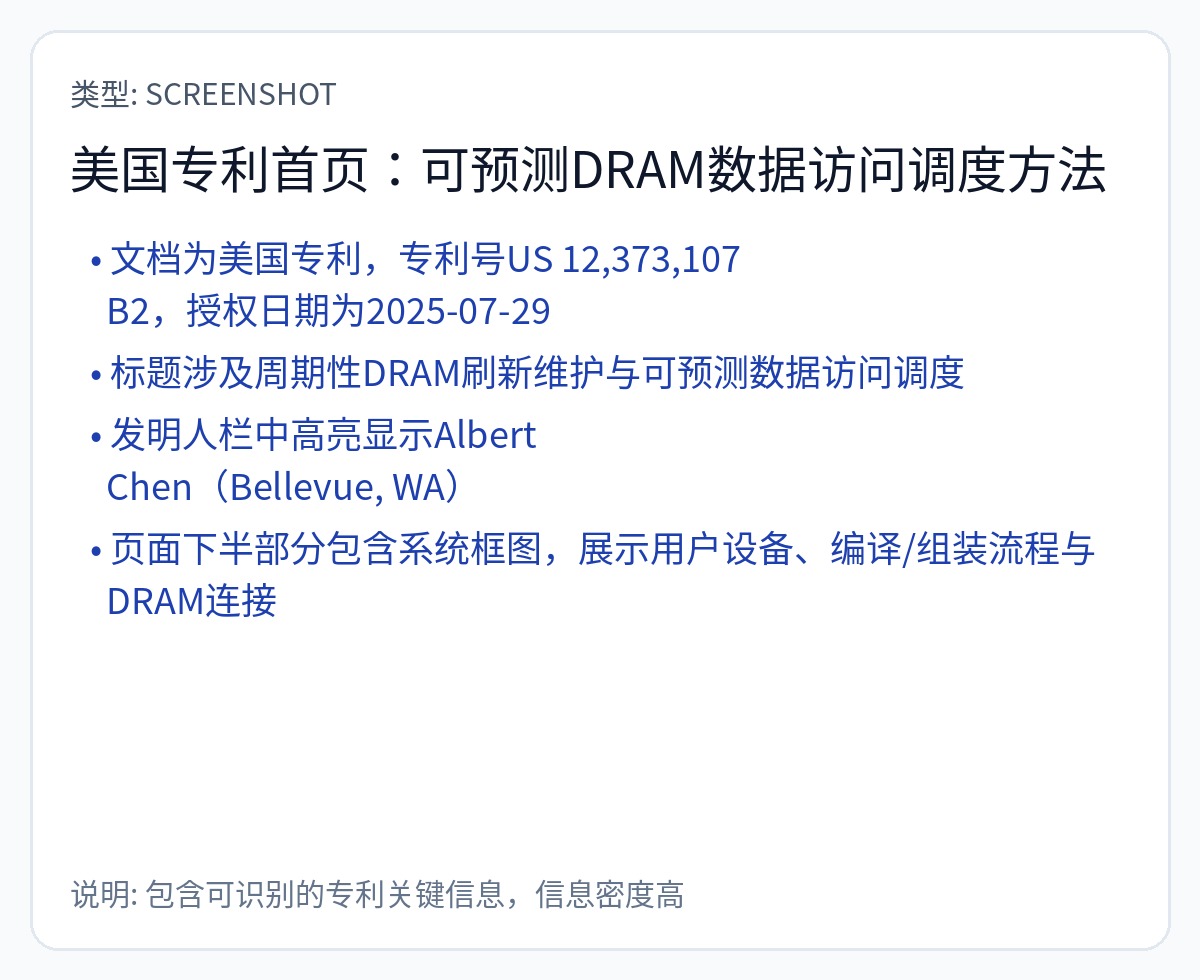
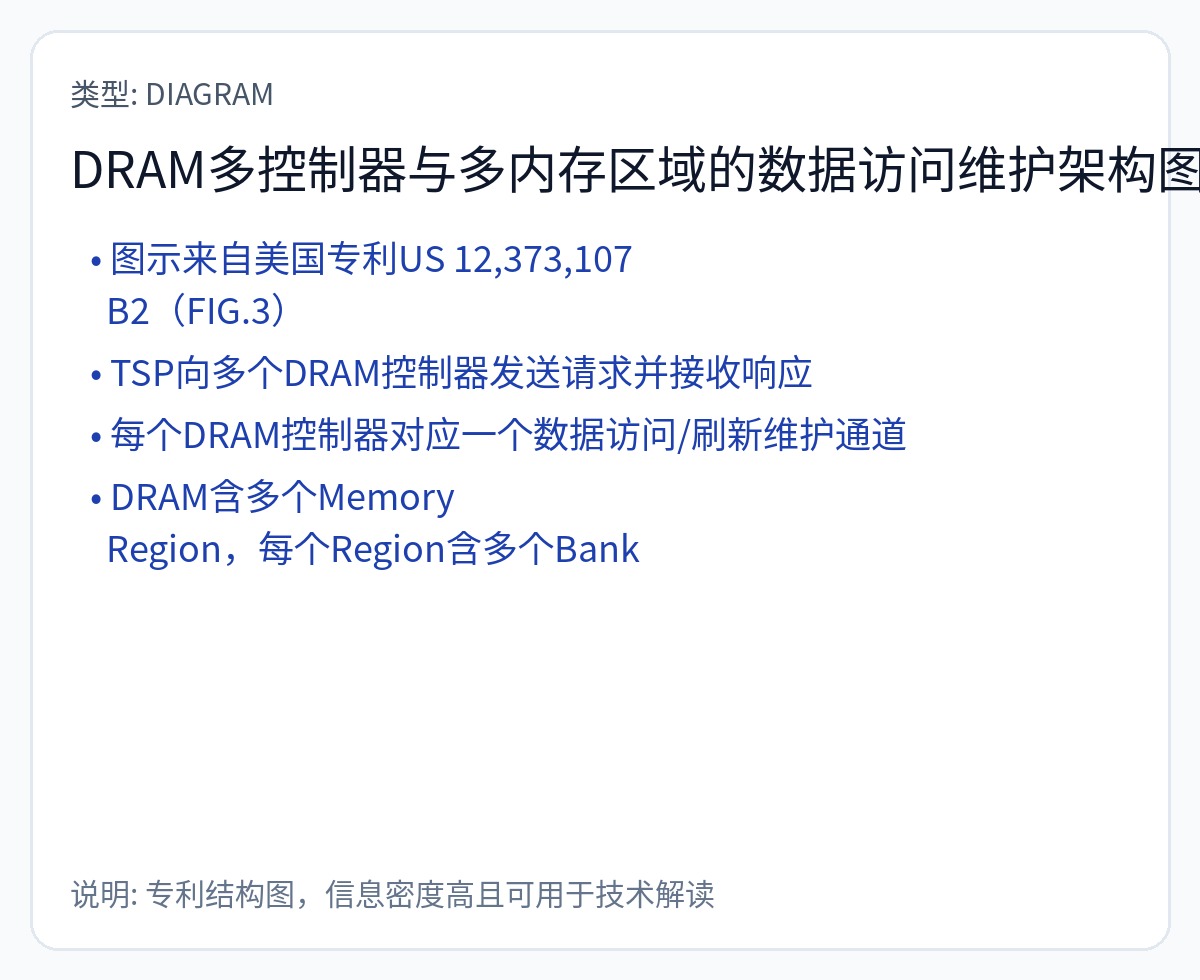
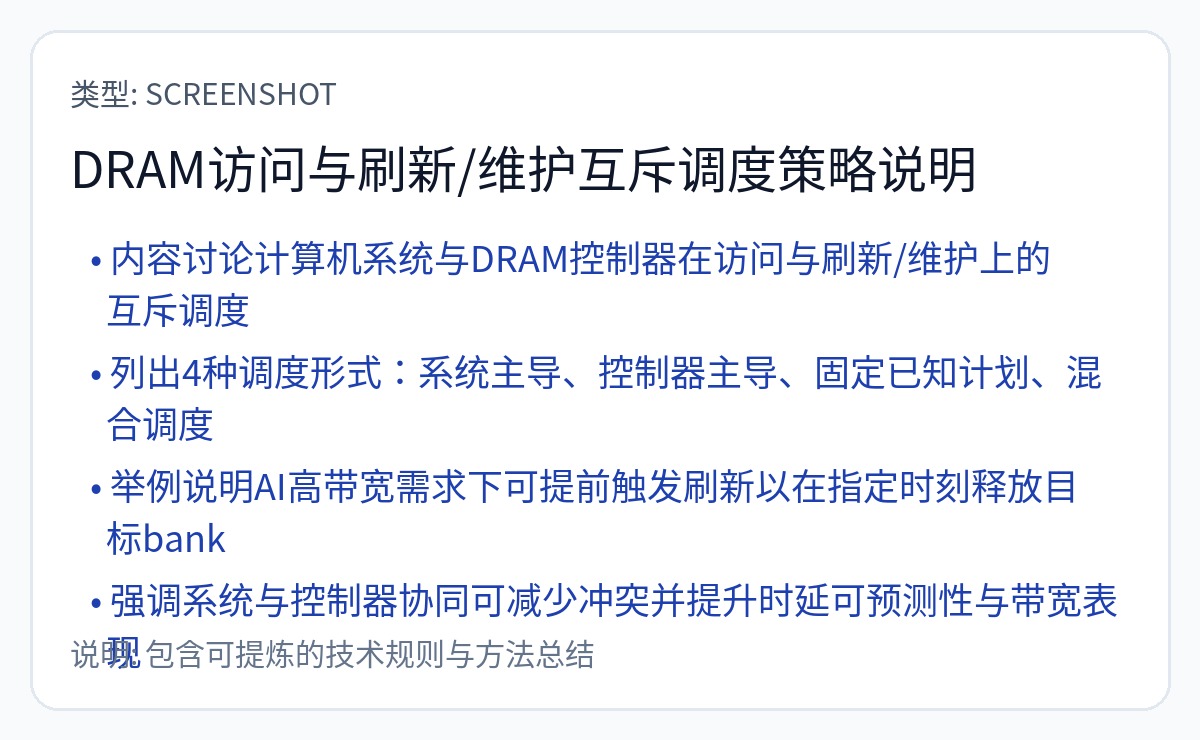
Abts 先生于 3 年前离开并加入 Nvidia。 Groq 的芯片均不使用任何类型的 DRAM。显然,这项使用调度数据包技巧使 DRAM 具有确定性的专利不起作用。否则,Groq 现在就已经添加了 DRAM。
这是他们实际使用的一项专利。
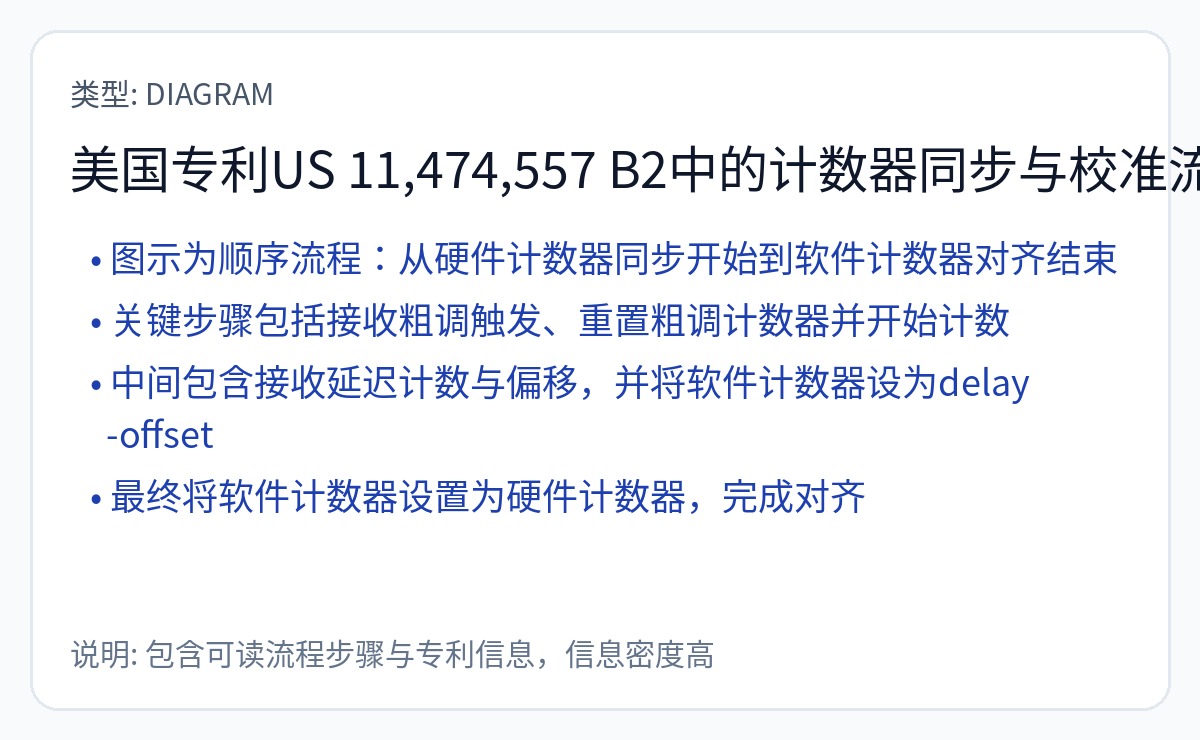
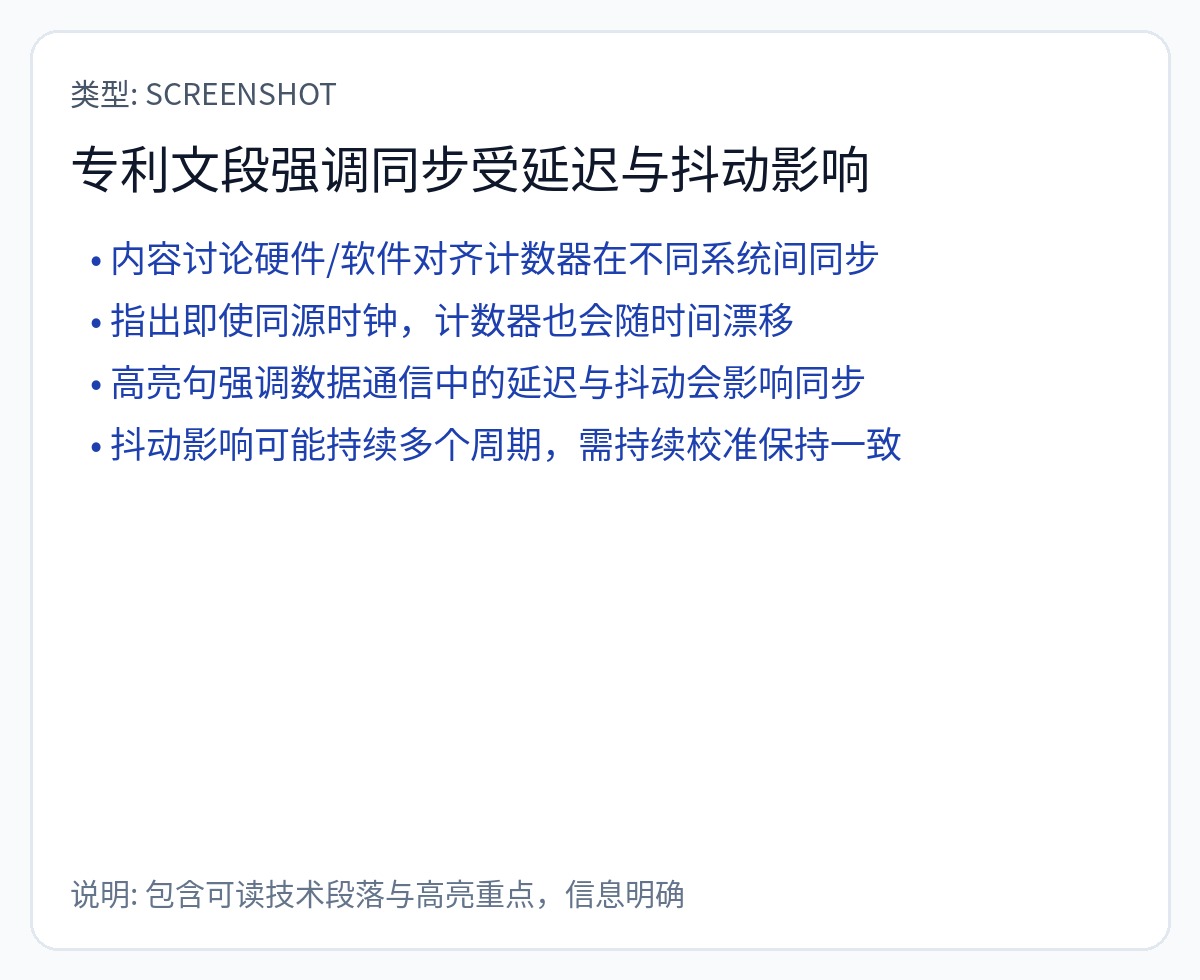
你说得对,SerDes 抖动和 PPM 时钟漂移会搞砸这个基于计数器的同步方案!
Groq 是有史以来最疯狂、最非正统、最不平衡的计算机。我和许多其他人一直在这令人厌恶的岁月里拉屎是有原因的!
但是......经过 6 年多的编译器工作并运行烧钱的推理云来学习如何使编译器变得更好......他们似乎已经找到了一些东西。
抛开你的偏见,假设编译器是功能性的,或者至少能够发挥作用。
想象一下,您是 Nvidia,拥有使 Groq 真正发挥其理论全部潜力所需的所有 IP。
$20B 很便宜。这是一次变革性的收购。比 Mellanox 大得多!
让我向您展示 Nvidia 如何让 Groq 充分发挥其潜力。
[6] Nvidia 与 Groq 风格架构令人难以置信的 IP 协同作用
台湾谣言工厂已经开始对 PCB 规格的泄露进行自慰,但这并没有抓住重点。供应链堕落者不知道 Groq 的真正价值是什么。
坦白说,我根本不在乎 Nvidia/Groq 在短期内使用 Groq V3 芯片拼凑出什么东西。 SF4X工艺节点比TSMC N6差,在某些情况下还比N7差哈哈。
Groq 架构和 Nvidia IP 具有令人难以置信的协同作用。他们将在 18 个月内让某些事情变得更好。
[6.a] 时钟转发 SerDes
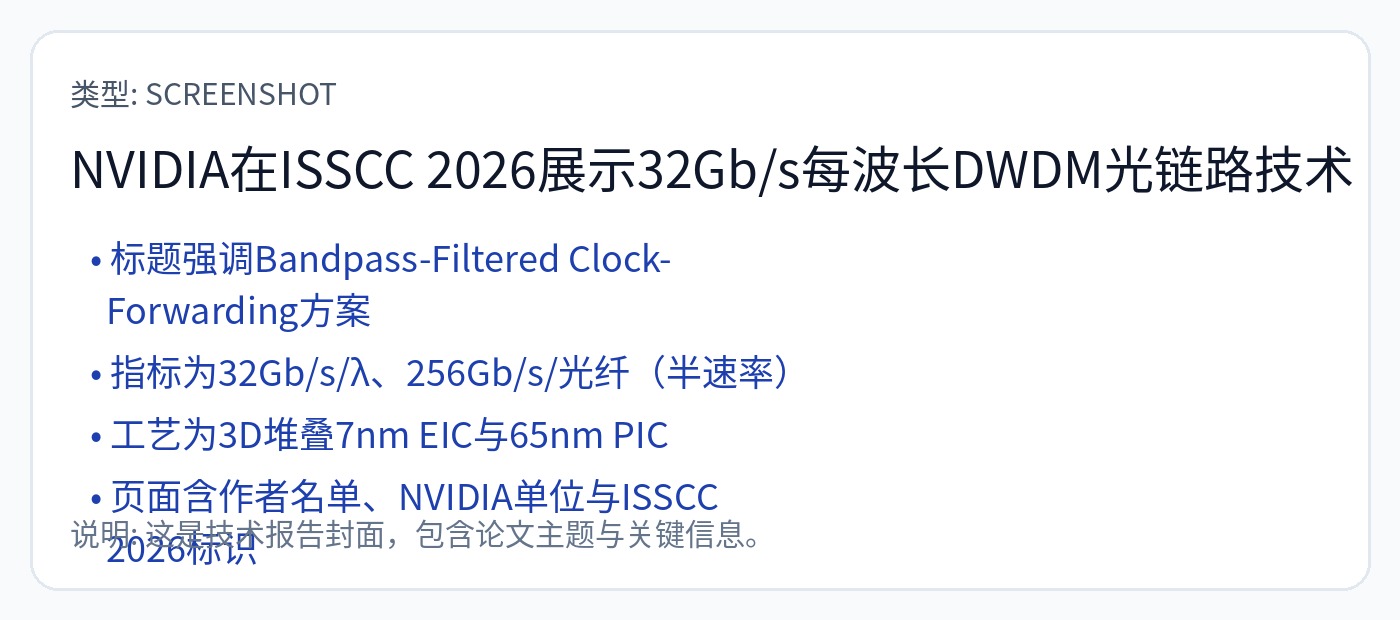
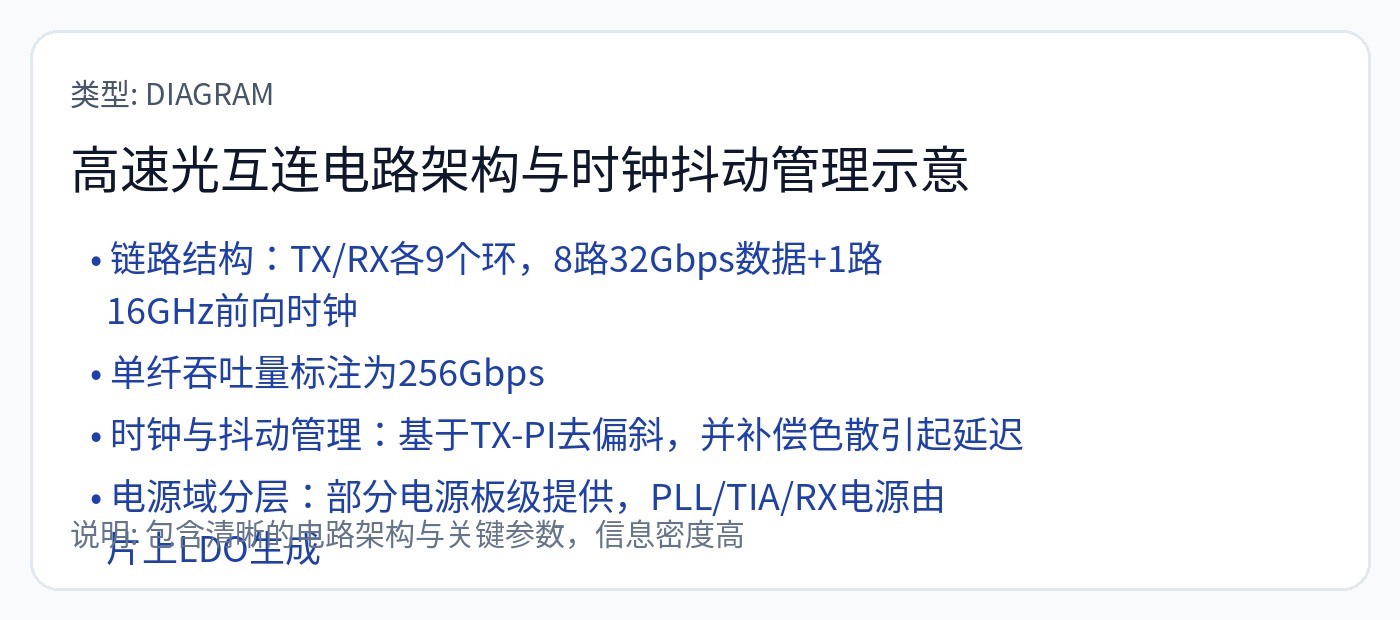
Nvidia 刚刚在 ISSCC 上展示了他们的光学时钟转发芯片到芯片链路。
我在这里有更详细的报道。
对于这篇文章,我将仅重新介绍时钟转发部分。
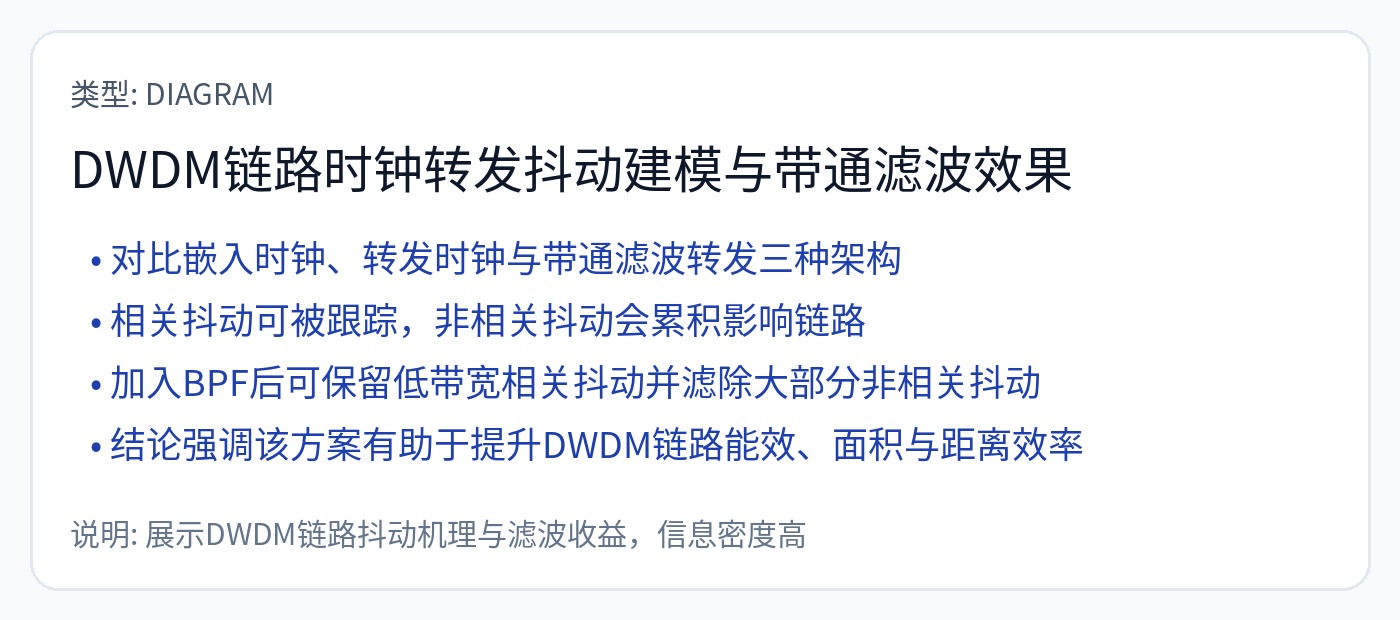
为转发时钟设计这个带通滤波器非常具有挑战性。 PVT 敏感性很高。

所有通道都支持接收转发时钟以优化良率。这会燃烧相当大的面积。他们这样做一定是有性能原因。
也许各个芯片的电串扰严重程度有所不同?
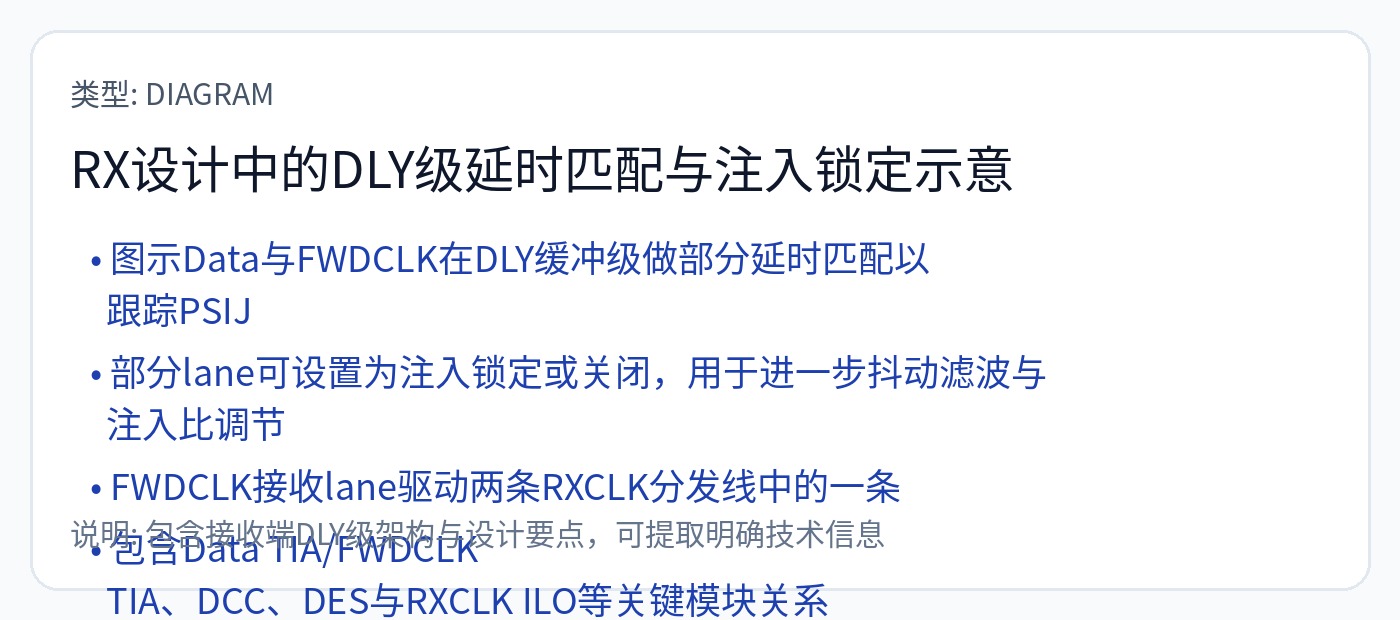
延迟匹配电路相当复杂。时钟正向通道和数据通道都有多个可调延迟元件。随时间的变化(VT 引起的)是一个大问题。注入锁定是一个关键策略。
https://en.wikipedia.org/wiki/Injection_locking
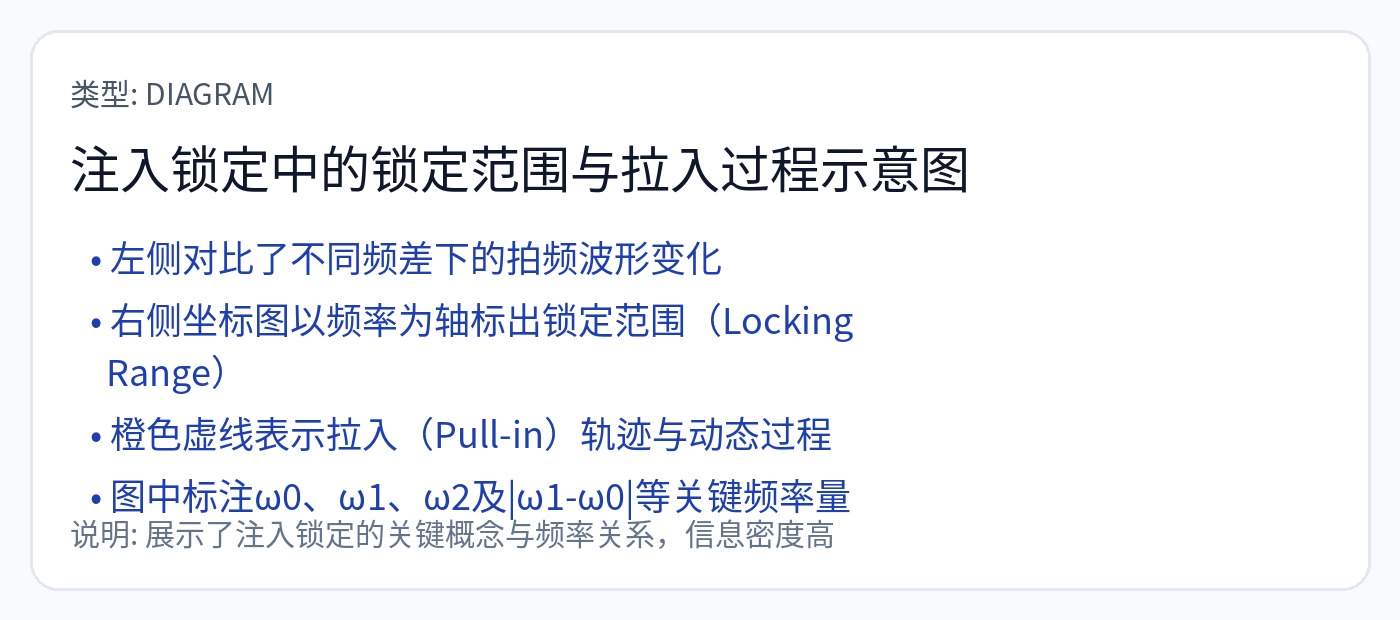
简而言之,注入锁定使用反馈路径来强化主要目标音调并衰减/消除谐波和其他正弦抖动源。

注入锁定带来巨大的增益,但电路很难调整。
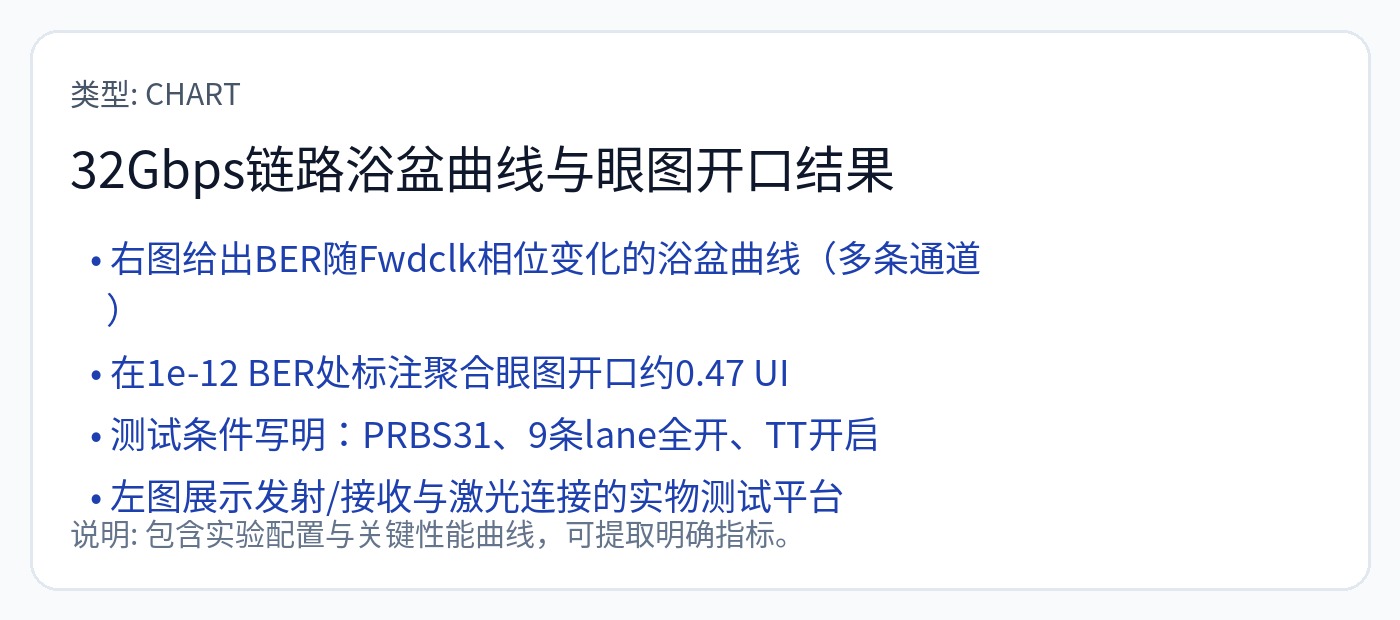
正向时钟相位变化约为 0.5 UI(单位间隔)或约 16 皮秒。
我向您保证,低于 16 皮秒的时钟精度比 Groq 通过其蹩脚的基于计数器的方案所达到的精度要好得多。
想象一下,GROQ 风格的硬件架构在通过光学器件进行真实时钟转发时可以表现出多么好的性能!!!!!!!!!!!!!!!!!!!!!!!!!!!
[6.b] 混合键合
改进 Groq 式架构的一种明显方法是使用混合键合来扩展 SRAM 暂存器。使用 TSMC 或 Intel Foundry 的混合绑定产品,您可以以最小的延迟损失获得大约 2 倍的容量。 Groq 没有资源来实现这一点。英伟达可以处理这个!
无论如何,延迟损失并不重要,因为编译器需要具有确定性,并且会提前取消延迟。
[6.c] 领先的散热团队
Groq 式架构的问题之一是热密度。虽然芯片的绝对功率不高,但部分执行逻辑变得非常非常热。
Nvidia 拥有世界上最好的液体冷却和热设计团队之一。热点将不再是问题。我怀疑由于热点问题,Groq 必须相对于他们的目标降低时钟频率。修复很容易,但性能却悬而未决。
[6.d] 理论光学全局时钟
Nvidia 的光学时钟转发 IP 对色散很敏感。
这令人惊讶。
https://www.rp-photonics.com/chromatic_分散.html
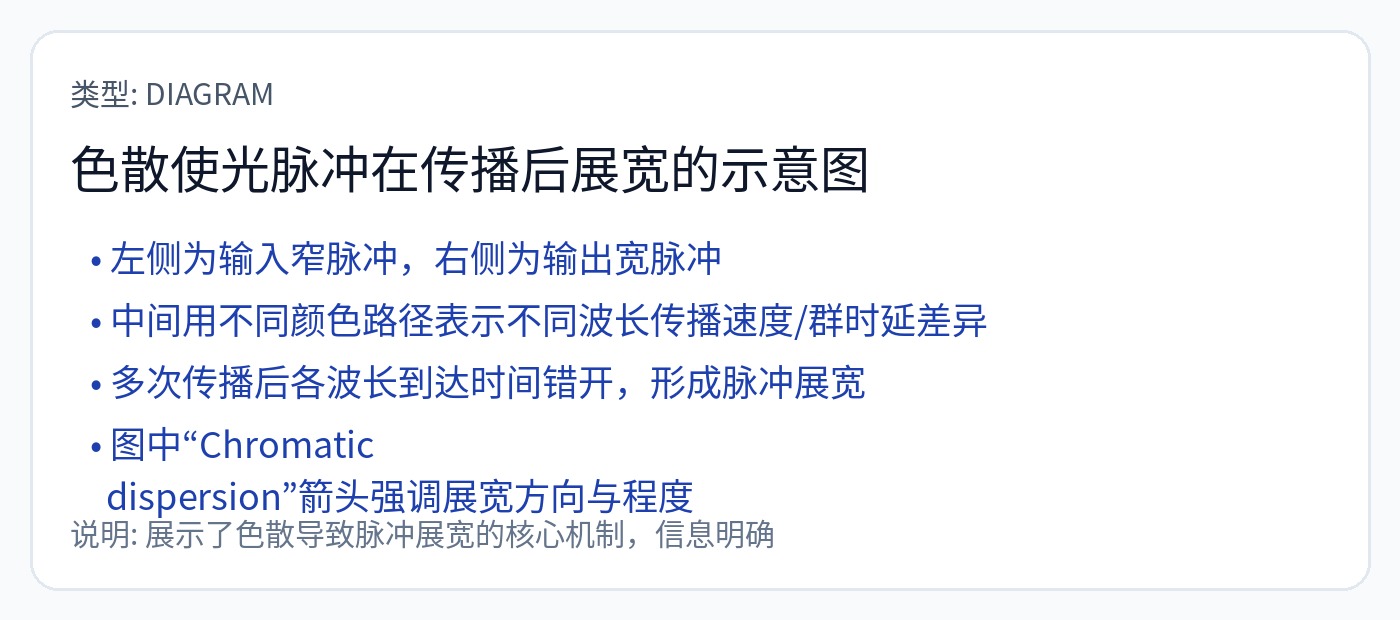
色散是一种在频域中展宽信号的光学现象。 DSP 解决这个问题的方法是简单地进行过采样。

色散是长距离 C 波段链路的典型问题。 O-band通常不关心这个。
这就是为什么我如此惊讶。 Nvidia 使用 O 频段,直观上这不是问题。显然,他们的系统极其敏感!
这表明Nvidia的光学时钟转发IP的覆盖范围有限。假设仅在机架内。
如果能够在整个数据中心内的各个机架上分配全局光学时钟……这对于 Groq 风格的架构来说真是太棒了。
光学原子钟在实验室和研究应用方面有着丰富的历史。
https://en.wikipedia.org/wiki/Optical_clock
最近,这项技术重新引起了数据中心的兴趣。
这确实是可能的。 Nvidia 光学集团是 Galaxy-Brain。他们可以做到这一点!
这些年来,Groq 编译器工程师一直在使用蹩脚的技巧和软件计数器来实现平庸的符号化。 Nvidia 拥有实现乔纳森·罗斯 (Jhonathan Ross) 最疯狂的梦想所需的独特知识产权,并真正释放世界上最不平衡计算机的疯狂潜力。
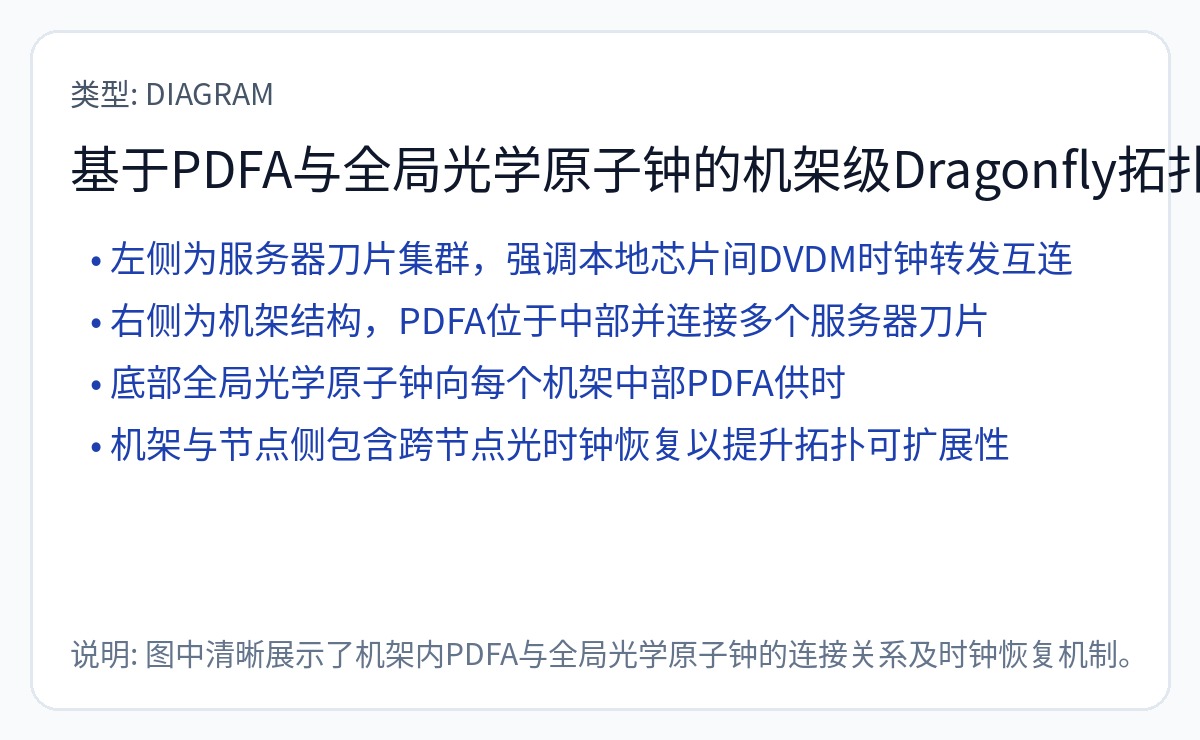
[7] 可能的 Nvidia/Groq 产品模型
[8] 任何白痴都可以建造一座桥梁 // 疯狂计算机的黄金时代
<全部>
订阅以在准备好后获得最终(完整)的帖子。
现代 Altera FPGA 概述
SN仁慈杀戮
等等,不,我想活下去
解释单位间隔
再次使用 nvidia ISSCC 纸张
精神错乱的谱系
脆性结构谱
groq 无法集成。一定是在岛上吗?
假设存在一些可以在岛上运行的人工智能工作负载
供应链角度
任何白痴都可以建造一座桥梁类比
为大家高兴
甚至大脑
恭喜 gif
WSE 桥梁
侮辱硬件差距